Table of Contents
1. Кому нужен серверный WebRTC?
Как все мы знаем, WebRTC — это peer-to-peer технология, реализующая канал коммуникации между двумя браузерами, для передачи аудио, видео и любых других данных с низкой задержкой. Технология совершенно бесплатная, и если вашему приложению нужно наладить общение в браузерах для двух удаленных участников, то вы можете добавить соответствующий javascript код на веб страницы и задача решена. Браузеры будут общаться напрямую, никакого сервера не требуется.
Серверный WebRTC выходит на сцену тогда, когда нужно чтобы участников было больше чем два, и данные от одного участника передавались сразу нескольким другим участникам.
В этом случае одним из участников может выступить сервер, который наладит общение «один на один» с первым участником, получит от него данные, затем наладит общение, тоже в режиме
«один на один» с другими участниками и перешлет им эти данные. Т.е. сервер держит множество peer-to-peer каналов связи и просто копирует данные во все эти каналы. В терминологии WebRTC такой сервер служит как Selective Forwarding Unit (SFU).
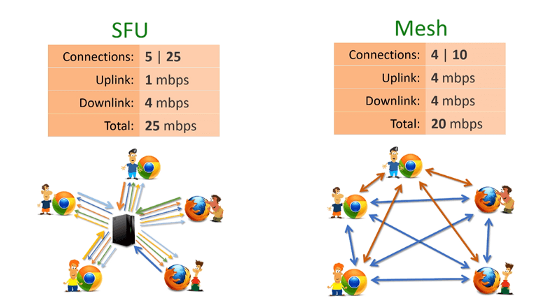
Однако, коммуникация в группе возможна не только с помощью SFU. Вы можете спросить – почему каждый не может посылать данные каждому, без всякого сервера, и будете совешенно правы. Это называется MESH – коммуникация.
Здесь есть два ключевых момента:
- В MESH схеме каждый из участников посылает и получает N-1 потоков данных, где N – размер группы. Т.е. требования на upload speed для каждого участника в MESH схеме увеличиваются с ростом группы. Тогда как в SFU схеме каждый участник всегда посылает только один поток. Не у каждого участника скорость соединения с сетью потянет посылку N-1 потоков.
- К сожалению, в MESH схеме браузер делает аудио-видео сжатие на каждый посылаемый поток. А это, как мы знаем, самы ресурсо-затратный процесс. В MESH схеме, приведенной выше, браузер каждого участника будеть сжимать видео VP8/VP9/H264 кодеком 4 раза. Это вызвано требованием WebRTC к адаптации качества данных к качеству канала – если связь не очень, то компрессия станет посильнее. Что есть хорошо, но влечет необходимость сжимать независимо на каждый канал (PeerConnection). Увы, на обычной машине браузер при сжатии 720p видео уже занимает 30% процессора, т.е больше трех каналов не потянет.
Из-за этих двух ключевых моментов MESH схема становится плохо реализуемой при растущем числе участников и приходится применять SFU схему.
Итак, при большом количестве участников коммуникации необходим сервер (SFU).
Давайте приведем примеры таких приложений, где сервер необходим:
- Видео конференции с множеством участников (всеми горячо любимый Zoom использует WebRTC сервер, как и все подобные сервисы).
- Видео наблюдение в реальном времени, когда от одной камеры видео посылается нескольким зрителям и записывающим устройствам. Системы безопасности, мониторинга.
- Интерактивные системы, такие как: интернет-аукционы, обучающие и другие веб-приложения, где требуется низкая задержка аудио/видео.
2. Если вам нужен-таки серверный WebRTC, что можно использовать в 2020 году?
Облачный сервис или своими силами?
Здесь вначале обычные для IT аргументы в пользу того либо другого: облако обеспечит и сэкономит IT-затраты на сервера, конфигурацию, масштабируемость. Но своими силами, если все получится (нет гарантии), то выйдет гораздо дешевле. Ведь за облачный сервис нужно помесячно платить.
Теперь к аргументам специфичным к описанным выше приложениям. Если у вас глобальная, огромная аудитория, в разных странах и регионах, то своими силами вам будет сложно все собрать вместе. К примеру, для аукциона Sotheby’s подойдет облачный сервис. Но если у вас 2-3 отделения компании в разных городах, 200-500 юзеров, и для них нужно организовать вебинар/конференции/обучение и т.п., то вы можете сами рентовать несколько серверов на AWS или подобных хостинг платформах, установить там софтверный WebRTC сервер, и все получится. Сервера могут даже быть у вас в компании, если скорость интернет-подключения позволяет. Ну и для всех решений меньших по масштабам, все можно сделать своими силами.
На текущий момент хорошо известны и проверены два облачных WebRTC сервиса: Millicast и Phenix. У обоих глобальное покрытие, хорошая связь между серверами на разных континентах (оно вам надо?) и действительно задержка видео (latency) на уровне пол-секунды и ниже.
Теперь поговорим про «своими силами».
Здесь вам понадобится WebRTC server software. Существуют 3 способа получить такой сервер.
- Сделать его самим, пользуясь открытым API. Самый известный из них это Google c++ WebRTC API. Также можно использовать GStreamer API. Интересна имплементация на Go: Pion WebRTC. Вам понадобятся квалифицированные c++ программисты и очень много терпения и времени на отладку. Про трудности этого подхода я подробно писал в своей предыдущей статье.
- Взять уже готовый бесплатный сервер с открытым кодом. Заслуживают упоминания Ant Media Server, Kurento, Janus, Jitsi. Эти сервера вполне подойдут для небольших проектов, хотя код там не оптимизирован, не оттестирован, встречаются баги. На github есть множество других проектов, еще более экспериментальных и сырых. Чтобы оптимизировать, заточить и починить баги, нужны, см. выше, собственные квалифицированные c++ программисты. Или нужно просить разработчиков этих продуктов все для вас заточить. Что делает продукт уже не бесплатным, а весьма дорогостоящим.
- Купить лицензию на платный сервер. Как правило, более законченный, надежный продукт и бесплатная поддержка. В этой категории следует отметить Red5 Pro, Flashphoner и Unreal Media Server.
Интеграция WebRTC сервера в ваши существующие продукты и решения.
Это самая проблематичная тема. Предположим, ваша компания выпускает софтверный продукт, в который надо внедрить WebRTC сервер. Пусть это система видеозаписи и наблюдения для терминалов аэропортов, вокзалов, транспортных узлов. Или медицинское оборудование с уже существующим сопровождающим софтом для трансляции и записи видео от эндоскопов, который нужно расширить до трансляции этого видео в браузер. Или система симуляции полетов, в которую надо внедрить возможность визуализации в браузере и/или интеракции с удаленным юзером. Мы постоянно сталкиваемся с подобными требованиями. У вашей существующей системы множество ограничений. Может не быть доступа в интернет. Никаких облаков. Нельзя на сервере открывать порты. Только Windows или только Linux. Иногда даже только определенная версия Windows, ведь существующий продукт заточен под нее. WebRTC сервер, добавляющийся в такую систему, должен быть подстроен под все эти ограничения.
Здесь, возможно, у вас нет иного выхода, чем брать открытый код сервера, такого как Ant Media Server или Janus, и менять его. Такова ситуация на Linux. Для Windows подойдет Unreal Media Server – это софт написанный и оптимизированный только для Windows OS.
WebRTC сервер – очень ресурсо-затратный
Помните об этом, когда планируете ваши ресурсы. Причины такой ресурсо-затратности описаны ниже, но вывод такой — масштабируемость достигается очень сильным процессором или добавлением физических серверов.
Привожу диаграмму тестов произведенных с Unreal Media Server v13.0 на AWS EC2 m4.2xlarge instance: Intel Xeon 8 cores CPU E5-2686 v4 @ 2.30 GHz, 32 Gb RAM, Windows Server 2016.
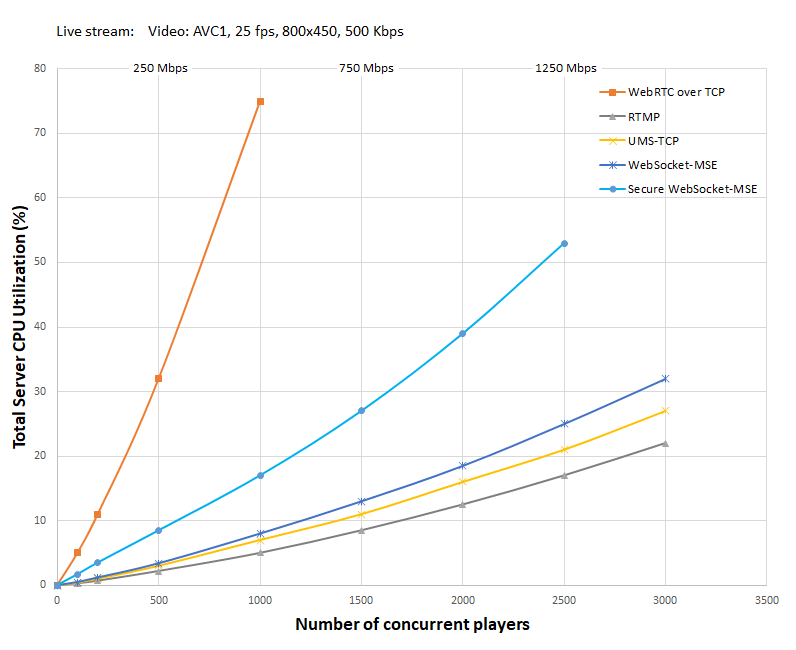
Как видно из диаграммы, при 1000 одновременных веб плеерах вот этой IP камеры загрузка процессора составляет 5% при RTMP протоколе, и 75% при WebRTC протоколе, т.е. WebRTC более чем в 10 раз ресурсо-затратнее чем RTMP.
Реализация WebRTC в медиа сервере – практика и политика
1. Стриминг в браузеры в реальном времени – решения нет. Или есть?
Вот уже примерно как 20 лет пропускная способность сетей и вычислительные возможности компьютеров позволяют сжатие и транслирование звука и видео по IP протоколу в режиме, близком к реальному времени. За это время центральными стандартизирующими организациями, такими как W3C и IETF, а также множеством больших и малых компаний, разработаны сотни стандартов и протоколов для эффективного сжатия, упаковывания, пересылки, синхронизации и проигрывания аудио-видео контента на компьютерах и мобильных устройствах. Видеозахвату, сжатию и трансляции по IP в реальном времени было уделено особое внимание, так как, во-первых, именно IP наиболее дёшев и общедоступен на всех уровнях, а во-вторых, технологии видеоконференций и видеонаблюдения жизненно необходимы и пользуются огромным спросом.
Казалось бы, столько лет прошло и столько работы проделано. Какие же прекрасные достижения в этой области мы можем наблюдать по прошествии 20 лет? Давайте снимем крышку ящика (конечно, это не ящик Пандоры и не «can of worms») и посмотрим, какие замечательные технологии и возможности стали доступны после многолетних трудов десятков тысяч талантливых софтверных инженеров. Программист из 1998 года, впервые переславший звук по сети, доктор, желающий простого, дешевого и надёжного телемедицинского решения, учитель, которому нужно провести удалённый урок – вот они открывают эту крышку, полные радужных надежд, и что они видят? В зловонной кипящей кастрюле, полной умопомрачительного маркетинга, циничного капитализма и отчаянных попыток энтузиастов поправить положение дел, плавают всякие кодеки, протоколы, форматы и аппы. Вот какой суп IT «сообщество» предлагает потребителю стриминга в реальном времени. Вылавливайте сами, что меньше пахнет, пробуйте, тестируйте, покупайте. Нет простого и эффективного решения. В отличие от стриминга, не требующего реального времени: там всё-таки уже лет 5 есть стандарт HLS, работающий на любых браузерах и устройствах, где solution provider может просто установить HLS segmenter у себя на сервере и спать спокойно.
Вот RTSP – его играют куча приставок и профессионального оборудования, но не играют браузеры. Вот RTMP – его не хочет играть Safari на iOS и не все Androids его играют. Его запрещает Chrome как неблагонадёжного. Вот MPEG2-TS – его тоже браузеры не играют. HTML5 Media Source Extensions (MSE) – хорош для видео сегментов длины 5-10 секунд (т.е. для HLS/Dash), но для коротких сегментов менее одной секунды — не всегда стабилен, работает по разному в разных браузерах и опять-таки не поддерживается на iOS.
Как, спрашивается, детскому саду посылать видео от камер, установленных в группах, родителям, которые хотят открыть браузер в любое время на любом устройстве, и без установки каких-то плагинов смотреть на своих детей в реальном времени? Почему таких услуг не предлагают все поголовно садики? Да потому что обеспечить такую услугу очень дорого. Нужно разработать Аппы для мобильных устройств, где видео будет проигрываться – ведь браузеры не играют. Нужно многое другое.
Давайте определим понятие «близко к реальному времени». Это меньше 5 секунд задержки для видеонаблюдения и менее 1 секунды для видеоконференции. Средняя задержка протокола HLS – 20-30 секунд. Может быть, для садиков еще как-то сойдёт, но для охранного видеонаблюдения, видеоконференций и вебинаров нужна другая технология.
Итак, до сих пор, точнее до лета 2017 года, не существовало единого стандарта или протокола для трансляции звука-видео в любой браузер на любом устройстве в реальном времени. Причины, по которым сложилась такая ситуация, мы рассмотрим в этой статье позже. Они не технического рода, эти причины. А пока посмотрим, что же всё-таки произошло летом 2017 года, что худо-бедно, но все же предоставило технологию, позволяющую решить вышеобозначенные задачи. Технология эта – WebRTC, о ней много написано и на этом ресурсе и вообще в сети. Ее уже нельзя назвать абсолютно новой и на момент написания этой статьи W3C считает WebRTC 1.0 завершённым проектом. Мы не будем здесь рассказывать, что такое WebRTC; если читатель не знаком с этой технологией, то предлагаем сделать поиск на хабре или в гугле и ознакомиться, для чего она применяется и как в общих чертах работает. Здесь мы лишь скажем, что технология эта была разработана для peer-to-peer коммуникации в браузерах, с помощью неё можно реализовать видео-чат и голосовые приложения без всякого сервера – браузер общается напрямую с браузером. WebRTC поддерживают все браузеры на всех устройствах, а летом 2017 года наконец-то и Apple снизошёл до нас и добавил её в свой Safari на iOS. Именно это событие сделало WebRTC самой универсальной и общепринятой технологией для реал-тайм стриминга в браузеры, со времен заката RTMP который начался в 2015 году.
Однако, при чем же здесь стриминг в браузеры от камер? А дело в том что WebRTC очень гибка в своей функциональности, и позволяет посылать звук-видео только одному из двоих участников (peers), а другому только принимать. Поэтому родилась идея адаптировать WebRTC в медиа серверах. Медиа сервер может получить видео от камеры, наладить коммуникацию с браузером, и договориться, что только он будет посылать, а браузер будет получать. Таким образом, Медиа Сервер может одновременно посылать видео от камеры многим браузерам / зрителям. И наоборот, медиа сервер может получать поток от браузера, и пересылать его, скажем, многим другим браузерам, реализуя столь желанную «one-to-many» функцию.
Значит, наконец-то всё образовалось? Акуна-матата, и садик сможет установить такой медиа сервер где-то на хостинге или на AWS, посылать один поток от каждой камеры туда, и оттуда он будет уже раздаваться в браузеры родителей, всё с задержкой не более одной секунды. В целом – да, жизнь налаживается. Но есть проблемы. И проблемы эти связаны с тем что WebRTC как бы притянут за уши для таких задач, он не для них проектировался и не совсем для них подходит. Проблемы, помимо совместимости кодеков, существуют прежде всего с масштабируемостью такого медиа сервера. То есть одновременно 100 родителей можно обслужить с одного серверского компьютера, а 500 – уже сложно. Хотя сеть позволяет. А посмотришь на загрузку процессора на сервере при 100 соединениях – она уже близка к 90%. Как так? Ведь всего-лишь посылаем звук-видео.
С таким же потоком, если посылать по RTMP протоколу в Flash player, то можно с одного сервера легко поддержать 2000 одновременных соединений. А по WebRTC всего 100?
Почему? Причины две: во-первых, сам WebRTC протокол значительно вычислительно дороже – там, к примеру обязательно шифрование всех данных, а оно забирает довольно много процессорного времени. И вторая причина, о которой мы расскажем поподробней – чрезвычайно неэффективная реализация протокола его создателем – Google, который и предоставляет исходный c++ код этой самой реализации для адаптирования в серверах, шлюзах и других приложениях, желающих поддержать WebRTC: webrtc.org/native-code
2. Google’s Native WebRTC API и его совместимость с медиа сервером
Напомним, что WebRTC создавался для передачи звука-видео из браузера в браузер и задачи поддержать множество одновременных соединений не было. Поэтому, и не только поэтому, реализация WebRTC в браузере совершенно наплевала на основной принцип проектирования и архитектуры технических систем – элегантность (ничего лишнего), эффективность, высокопроизводительность. Акцент был сделан на надежность и справляемость с ошибками и крайними ситуациями в сети – потерю пакетов, соединений и т.п. Что, конечно, есть хорошо. Однако, при детальном рассмотрении, выясняется, что это единственное, что есть хорошо в гугльской реализации WebRTC.
Давайте рассмотрим основные моменты, из-за которых применение гугльской реализации WebRTC для медиа серверов крайне проблематично.
2.a Кода в 10 раз больше, чем должно быть и он крайне неэффективен
Это проверенная цифра. Для начала вы сгружаете около 5 гигабайт кода, из которых к WebRTC имеет отношение только 500 мегабайт. Затем вы пытаетесь избавиться от ненужного кода. Ведь вам для нужд медиа сервера не нужен энкодинг/декодинг; сервер должен только получить контент и переслать его всем желающим. Когда вы убрали всё ненужное, что смогли (а смогли вы убрать гораздо меньше, чем хотелось бы), всё равно осталось 100 мегабайт кода. Это чудовищная цифра. Именно она в 10 раз больше, чем должна быть.
Кстати, на этом месте многие скажут – как это не нужен энкодинг/декодинг? А транскодинг из AAC в Opus и обратно? А транскодинг VP9->H264? Если вы собираетесь делать такой транскодинг на сервере, то вам и 5 одновременных соединений не потянуть. Транскодингом, если он действительно необходим, должен заниматься не медиа сервер, а другая программа.
Но давайте вернемся к проблеме раздутого кода и проиллюстрируем ее. Как вы думаете, какова глубина стека вызовов функций при отправке уже сжатого видео фрейма? Один вызов winsock (на Windows) функции send или sendto (WSASend / WSASendTo)? Нет, нужно, конечно, проделать ещё кое-какую работу. В случае WebRTC, нужно упаковать фрейм по RTP протоколу и зашифровать его, что в сумме дает нам SRTP протокол. Нужно сохранить фрейм на случай потери пакетов, чтобы выслать потом ещё раз. Сколько c++ объектов и threads (потоков) должно быть в это вовлечено?
Вот как это делает WebRTC 61:
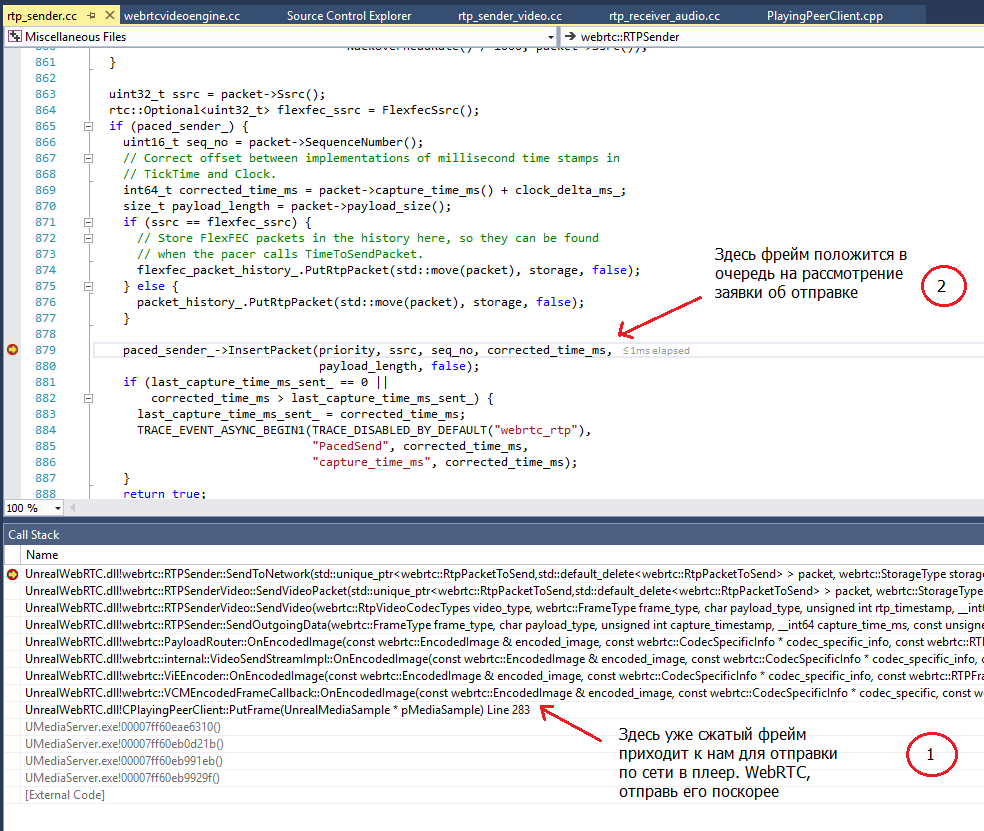
Как видно из этого скриншота, с момента когда мы подаём в WebRTC сжатый фрейм, до момента когда его положат в очередь объекта Paced_Sender, глубина стека вызовов равна 8 (!) и задействовано 7 объектов!
Затем отдельный thread (поток) PacedSender вытаскивает наш фрейм из очереди и посылает его дальше в обработку:
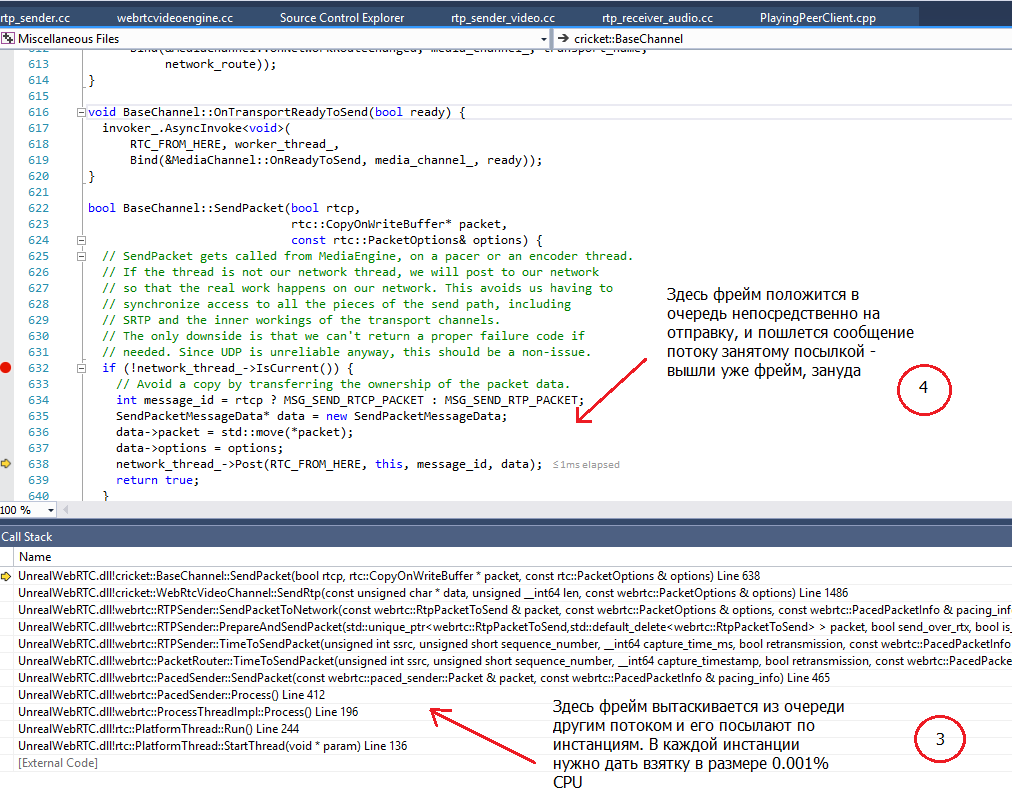
И наконец, мы пришли к этапу 4, где уже RTP-упакованный и зашифрованный фрейм положится в очередь на отправку в сеть, которой занимается ещё один поток. К этому моменту глубина стека вызовов (на потоке PacedSender) равна 7, и вовлечено ещё 3 новых объекта. Поток, занятый отправкой, вызовет конечные WSASend/WSASendTo также после 3-4 вложенных вызовов функций и вовлечет еще 3-4 новых объекта.
Итак, мы увидели 3 потока, каждый из которых проделывает огромную работу. Каждый, кто программировал подобные системы, имеет представление о том как делаются такие вещи, и что реально должно быть сделано. По нашим оценкам, как минимум 90% объектов и кода здесь – лишние и нарушают принципы объектно-ориентированного программирования.
2.b На одно соединение отводится 4-5 threads (потоков)
Спору нет, с количеством потоков в данном примере всё в порядке. Нужно обеспечить асинхронную обработку, никого не блокировать, и все 3 потока нужны. В целом, на один PeerConnection WebRTC отводит в 4-5 потоков. Ну можно было бы уложиться в 3. Но не меньше. Проблема в том что это – на каждое соединение! В сервере, к примеру, можно сохранить 3 потока, но они будут обслуживать все соединения вместе, а не отводить 3 потока на каждое соединение. Пул потоков – несомненное серверское решение для таких задач.
2.c Асинхронные сокеты, работающие через windows messages
Гугльский WebRTC код на Windows использует асинхронные сокеты через WSAAsyncSelect. Серверные программисты знают, что использование функции select на сервере – самоубийство, и WSAAsyncSelect, хотя и улучшает ситуацию, но не на порядок. Если вы хотите поддержать сотни и тысячи соединений, на Windows есть решение лучше, чем асинхронные сокеты. Должны быть задействованы Overlapped sockets и IO Completion Ports, посылающие нотификации пулу потоков, выполняющему работу.
2.d Заключение
Итак, можно заключить: применение гугльского кода WebRTC, без больших изменений, к медиа серверу — возможно, но сервер не сможет потянуть сотни одновременных коннекций. Решения здесь может быть два:
Сделать серьезнейшие изменения в гугльском коде – работа, без преувеличения, близкая к невозможному – ведь все эти объекты очень плотно подогнаны друг к другу, не энкапсулируют функциональность, не являются независимыми блоками, выполняющими определённую работу, как это должно быть. Задействовать их без изменения в других сценариях – невозможно.
Не использовать гугльский код вовсе, а реализовать всё самим, используя открытые библиотеки, такие как libsrtp и ему подобные. Возможно, это – правильный путь, но помимо того, что это также огромная работа, вы можете столкнуться с тем, что ваша имплементация будет не совсем совместима с гугльской, и, соответственно, не будет работать, или не во всех случаях будет работать, к примеру, с хромом, чего допустить никак нельзя. Вы можете потом долго спорить с ребятами из гугла, доказывать, что вы соблюли стандарт, а они – нет, и будете тысячу раз правы. Но они, в лучшем случае, скажут – «исправим, может быть как-нибудь потом». Вам нужно подстраиваться под хром прямо сейчас. И точка.
3. Почему все так грустно
Такая ситуация со стримингом в браузеры в реальном времени – очень характерная иллюстрация того, к чему иногда приводит “business driven technology”. Технология, мотивируемая бизнесом, развивается в том направлении, в каком она необходима бизнесу и постольку, поскольку она угодна этому бизнесу. Именно благодаря бизнес-подходу у нас сейчас есть персональные компьютеры и мобильные телефоны — никакое правительство или центральное плановое министерство никогда не могло бы быть так заинтересовано разработать и внедрить в массы все эти потребительские технологии. Частный бизнес, мотивируемый личной выгодой своих хозяев, сделал это как только появилась техническая возможность.
Давно известно, понято и принято, что второстепенные потребительские товары и услуги, те, без которых можно спокойно прожить, лучше развиваются частным бизнесом, тогда так жизненно необходимые, основные для человека вещи – энергия, дороги, полиция и школьное образование — должно развиваться центральными, контролируемыми государством, институтами.
Мы, дети Советского Союза и менталитета «давайте сделаем технически правильную и сильную технологию, чтобы люди могли ей пользоваться и всем было хорошо», могли бы, конечно, утверждать, что в плановой советской системе (если бы вдруг правительство решило), технология стриминга по IP в реальном времени могла бы быть разработана и внедрена за год и была бы на порядок лучше всего того, что бизнес наработал сейчас за 20 лет. Но мы также понимаем, что потом она не развивалась бы, устарела и, в конце концов, в далёкой перспективе, всё же проиграла бы какой-нибудь коммерческой западной технологии.
Поэтому, так как без стриминга-шмиминга вполне можно обойтиться, он справедливо отдан на откуп частному бизнесу. Который развивает его в своих интересах, а не в интересах потребителя. Как так не в интересах потребителя? А как же спрос-предложение? Что потребителю надо, то бизнес и предложит? А вот не предлагает. Все потребители кричат – Google, поддержи AAC audio в WebRTC, но Google никогда на это не пойдет, хотя ему раз плюнуть, чтобы это сделать. Apple абсолютно на всех наплевал и ничего вообще не внедряет из столь необходимых потоковых технологий у себя в гаджетах. Почему? Да потому что не всегда бизнес делает то что надо потребителю. Он не делает этого тогда, когда является монополистом и не боится потребителя потерять. Тогда бизнес занят укреплением своих позиций. Вот Google купил в последние годы кучу производителей звуковых кодеков. И проталкивает теперь Opus audio, и заставляет весь мир делать транскодинг AAC->Opus для соответствия с WebRTC, так как вся технология давно перешла на AAC audio. Google оправдывает это якобы тем, что AAC – платная технология, а Opus — бесплатная. А на самом деле, это делается для того, чтобы установить свою технологию как стандарт. Как когда-то сделал Apple со своим убогим HLS, который нас заставили любить, или как еще раньше сделал Adobe со своим невменяемым RTMP протоколом. Гаджеты и браузеры – всё-таки довольно технически сложные вещи для разработки, отсюда и возникают монополисты, отсюда, как говорится, воз и ныне там. А W3C и IETF спонсируются теми же самыми монополистами, поэтому менталитета «давайте сделаем технически правильную и сильную технологию, чтобы люди могли ей пользоваться и всем было хорошо» — там нет и не будет. А должен был бы быть.
Какой выход из этой ситуации? Видимо, просто ждать, когда «правильная» business-driven технология, результат конкуренции и всяких других прекрасностей, наконец, разродится чем-то демократичным, подходящим для простого сельского доктора, чтобы тот со своим обычным интернетом смог давать телемедицинские услуги. Ведь, надо сделать поправку, не для простого сельского доктора, а для тех, кто может платить большие деньги, бизнес давно предлагает решения по стримингу в реальном времени. Хорошие, надёжные, требующие выделенных сетей и специального оборудования. Во многих случаях и не работающих по IP протоколу. Который – и это ещё одна причина такой печальной ситуации — и не был создан для для реального времени, и не всегда гарантирует его обеспечить. Не всегда, но не в жизненно-важных ситуациях вполне подходит на данный момент. Так что давайте пробовать WebRTC. Пока из всех зол он является наименьшим и вполне демократичным. За что, всё-таки, нужно сказать спасибо Гуглу.
4. Немного о медиа серверах, реализующих WebRTC
Wowza, Flashphoner, Kurento, Flussonic, Red5 Pro, Unreal Media Server — вот некоторые из медиа серверов, поддерживающие WebRTC. Они обеспечивают публикацию видео из браузеров на сервер и трансляцию видео в браузеры по WebRTC от сервера.
Проблемы, описанные в этой статье, по разному и с той или иной степенью успеха, решены в этих софтверных продуктах. Некоторые из них, например Kurento и Wowza, делают аудио-видео транскодинг прямо в сервере, другие, к примеру Unreal Media Server, транскодинга сами не делают, но предоставляют для этого другие программы. Некоторые сервера, такие как Wowza и Unreal Media Server, поддерживают стриминг по всем соединениям через один центральный TCP и UDP порт, ведь сам WebRTC отводит отдельный порт на каждое соединение, так что провайдеру приходится открывать множество портов в firewall, что создает проблемы с безопасностью.
Существует множество моментов и тонкостей, реализованных во всех этих серверах по разному. Насколько это все подходит потребителю, судить Вам, уважаемые пользователи.
Опыт использования WebRTC
Что лучше использовать при разработке софта — нативные или веб-технологии? Холивар по этому поводу закончится ещё не скоро, но мало кто станет спорить, что нативные функции полезно продублировать для использования в браузерах или WebView. И если когда-то приложения для звонков существовали исключительно отдельно от браузера, то теперь их легко реализовать и в вебе. Разработчик Григорий Кузнецов объяснил, как пользоваться технологией WebRTC для P2P-соединений.
— Как вы все знаете, в последнее время появляется довольно много приложений, в основу которых заложен прямой обмен данными между двумя браузерами, то есть P2P. Это всевозможные мессенджеры, чаты, звонилки, видеоконференции. Также это могут быть приложения, которые производят какие-то распределенные вычисления. Пределы фантазии никак не ограничиваются.
Как же нам сделать подобную технологию? Представим, что мы хотим совершить звонок из одного браузера в другой. И пофантазируем, какие нам нужны шаги, чтобы этой цели достичь. В первую очередь кажется, что звонок — это наша картинка, наш голос, изображение, и нужно получить доступ к медиаустройствам, подключенным к компьютеру: к камере и к микрофону. После того, как вы получите доступ, вам необходимо, чтобы ваши два браузера, два клиента, друг друга нашли. Нужно помочь им как-то соединиться, достучаться, передать метаинформацию.
Когда вы достучитесь, необходимо начать передавать данные в режиме P2P, то есть обеспечить передачу медиапотоков. Все необходимые пункты у нас есть, мы готовы реализовать свой классный новый велосипед. Но это шутка, мы с вами инженеры и понимаем, что это дорого, неоправданно и рискованно. Поэтому как классические инженеры давайте сначала подумаем, какие решения уже существуют.
В первую очередь — старая умирающая технология Adobe Flash. Она действительно умирает, и компания Adobe прекратит ее поддержку уже в 2020 году. Технология действительно позволит вам получить доступ к вашим медиаустройствам, внутри нее вы сможете реализовать всю необходимую механику, чтобы помочь браузерам соединиться, чтобы они начали передавать информацию P2P, но вы опять изобретете свой велосипед, потому что нет единого стандарта, единого подхода к реализации данного способа передачи данных.
Вы можете написать для браузера плагин. Так работает Skype для тех браузеров, которые не поддерживают более современные технологии. Вам придется реализовывать свой велосипед, потому что нет единого стандарта, а еще это плохо для пользователей, так как пользователю придется себе в браузер инсталлировать какой-то плагин, совершать дополнительные действия. Пользователи этого не любят и не хотят делать.
И есть технология WebRTC — с помощью нее работают Google Hangouts, Facebook Messenger. Компания Voximplant использует ее, чтобы вы могли совершать свои звонки. Давайте на ней остановимся подробнее. Это новая развивающаяся технология, она появилась в 2011 году и продолжает развиваться. Что же она позволяет делать? Получить доступ к камере и микрофону. Установить P2P-соединение между двумя компьютерами, двумя браузерами. Естественно, она позволяет передавать медиапотоки в режиме реального времени. Кроме того, она позволяет передавать информацию, то есть любую бинарную дату вы тоже можете передавать P2P, можете сделать свою систему распределенных вычислений.
Важный момент: WebRTC не предоставляет браузерам способ найти друг друга. Мы можем сформировать всю необходимую метаинформацию о нас любимых, но как одному браузеру узнать о существовании другого? Как их соединить? Рассмотрим пример.
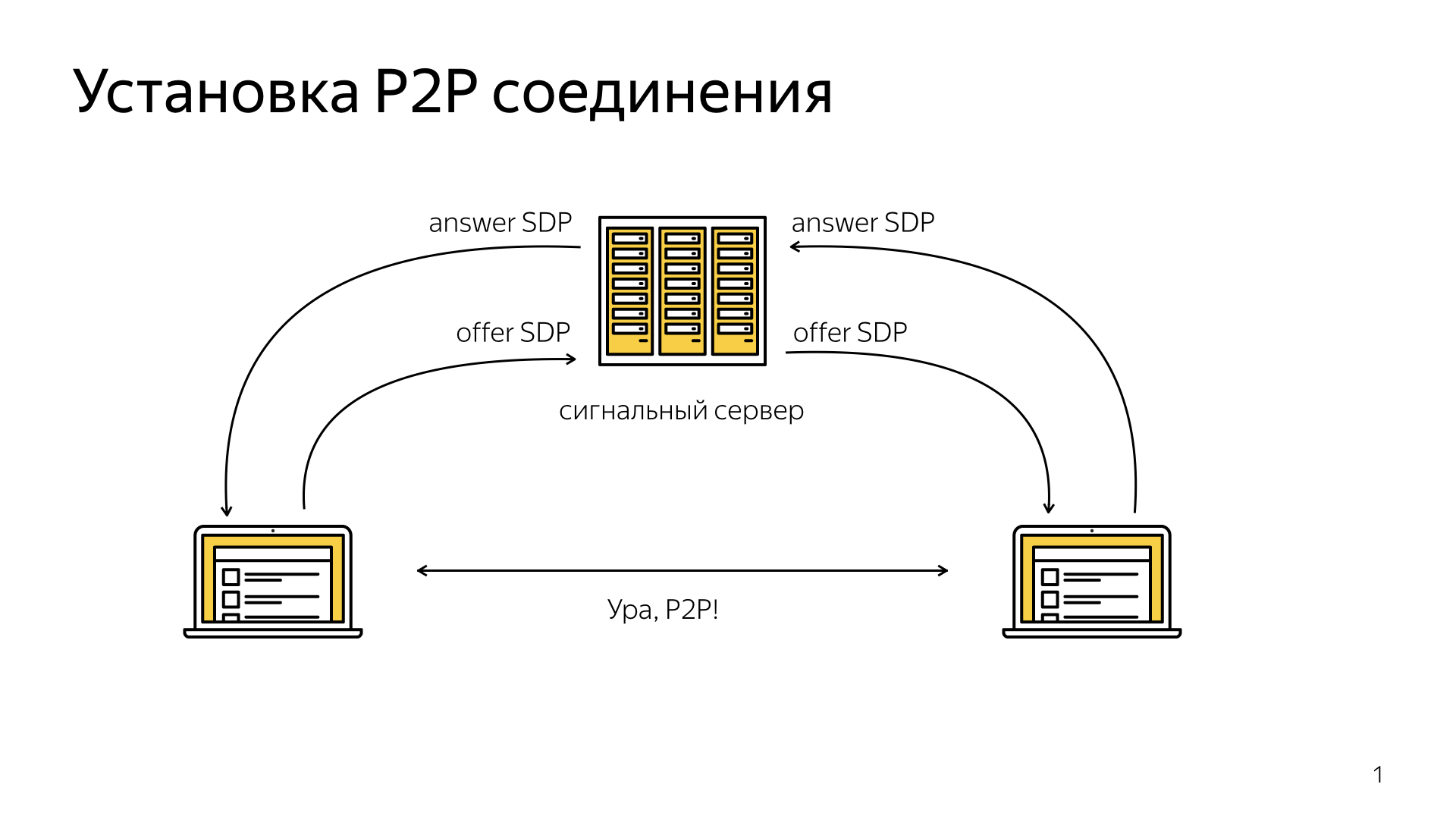
Есть два клиента. Первый клиент желает совершить звонок второму клиенту. WebRTC дает всю необходимую информацию, чтобы себя обозначить. Но остается открытым вопрос, как одному браузеру найти другой, как эту метаинформацию переслать, как проинициализировать вызов. Это дается на откуп разработчикам, мы можем использовать абсолютно любой способ, взять эту метаинформацию, распечатать на бумажке, отправить курьером, другой ее будет использовать, и все будет работать.
А можем придумать некоторый сигнальный механизм. В данном случае это сторонний механизм, который позволит нам, если мы знаем о наших клиентах, обеспечить передачу между ними некоторой информации, которая необходима для установки соединения.
Рассмотрим пример с использованием сигнального сервера. Есть сигнальный сервер, который держит постоянное соединение с нашими клиентами, например, по веб-сокетам или с помощью HTTP. Первый клиент формирует метаинформацию, и с помощью веб-сокетов или HTTP пересылает ее на сигнальный сервер. Пересылает также какую-то часть информации, с кем именно он хочет соединиться, например, никнейм или еще какую-то информацию.
Сигнальный сервер по этому идентификатору устанавливает, какому именно клиенту нужно переадресовать нашу метаинформацию, и пересылает ее. Второй клиент берет ее, использует, устанавливает себе, формирует ответ, и с помощью сигнального механизма пересылает ее на сигнальный сервер, тот в свою очередь ретранслирует ее первому клиенту. Таким образом оба клиента в данный момент обладают всей необходимой датой и метаинформацией, чтобы установить P2P-соединение. Готово.
Давайте чуть подробнее рассмотрим, чем же именно обмениваются клиенты, они обмениваются SDP-датаграммой, Session Description Protocol.

Это, по сути, текстовый файл, который содержит всю необходимую информацию, чтобы установить соединение. Там есть информация об IP-адресе, о портах, которые используются, о том, какая именно информация гоняется между клиентами, что это такое — аудио, видео, какие кодеки используются. Все, что нам необходимо, там есть.
Обратите внимание на вторую строчку. Там указан IP-адрес клиента, 192.168.0.15. Очевидно, это IP-адрес компьютера, который находится в какой-то локальной сети. Если у нас два компьютера, каждый из которых находится в локальной сети, каждый из которых знает свой IP-адрес в рамках этой сети, хотят созвониться. Получится ли у них сделать это с такой датаграммой? Очевидно, нет, они же не знают внешних IP-адресов. Как быть?
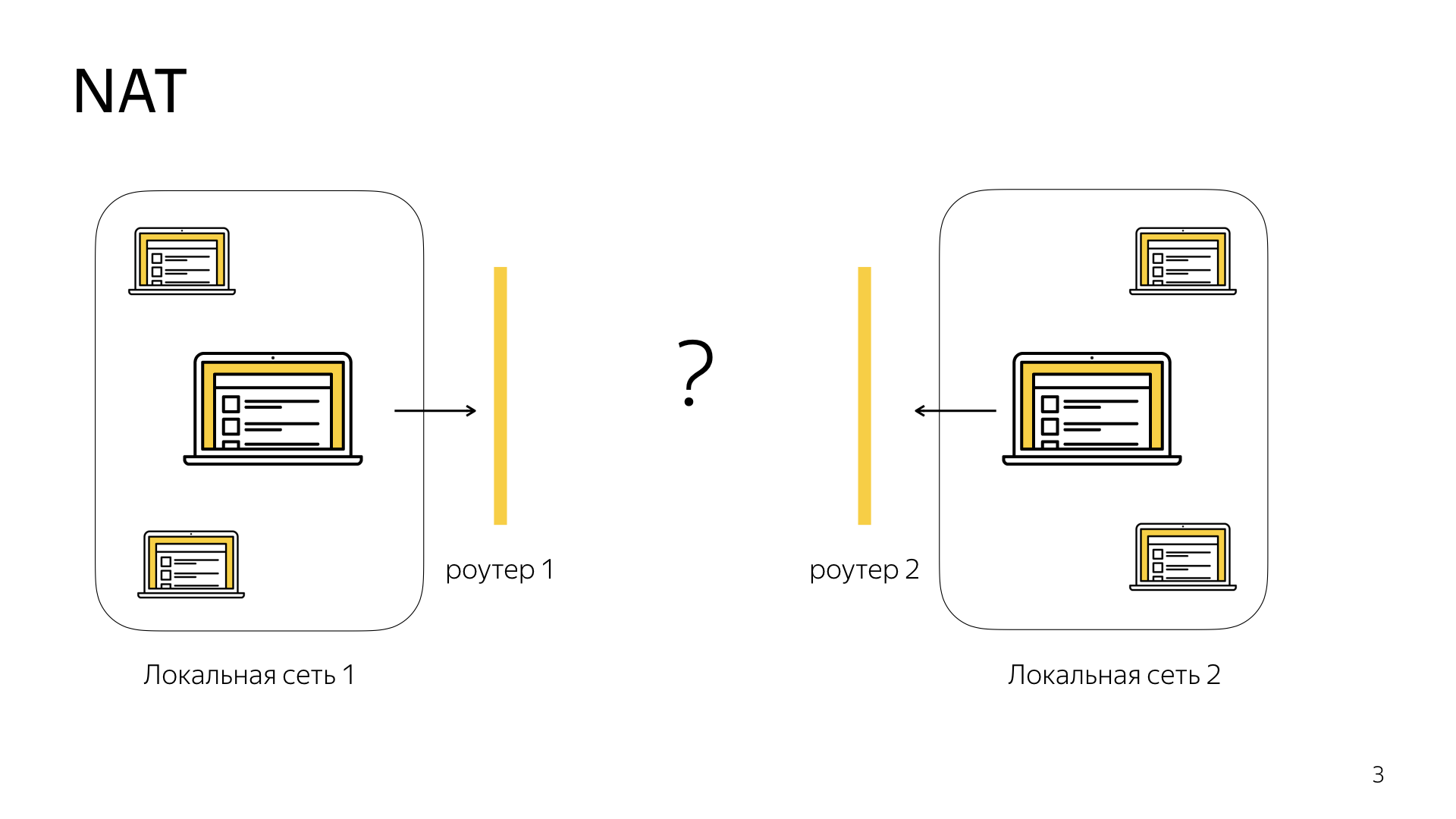
Отойдем в сторону и посмотрим, как работает NAT. В интернете многие компьютеры скрыты за роутерами. Есть локальные сети, внутри которых компьютеры знают свои адреса, есть роутер, который обладает внешним IP-адресом, и наружу все эти компьютеры торчат с IP-адресом этого роутера. Когда пакет от компьютера в локальной сети идет на роутер, роутер смотрит, куда его нужно переадресовать. Если на другой этой локальной сети, то он просто его ретранслирует, а если нужно его отправить вовне, в интернет, то составляется таблица маршрутизации.

Мы заполняем внутренний IP-адрес компьютера, который желает переслать пакет, его порт, ставим внешний IP-адрес, IP-адрес роутера, и делаем также подмену порта. Для чего она нужна? Представим, что два компьютера обращаются к одному и тому же ресурсу, и нам нужно правильно смаршрутизировать ответные пакеты. Мы их будем идентифицировать по порту, порт будет по каждому из компьютеров уникальным, в то время как внешний IP-адрес будет совпадать.
Как жить, если есть NAT, если компьютеры торчат наружу под одним IP-адресом, а внутри знают о друг друге по другим?
На помощь приходит фреймфорк ICE — Internet Connectivity Establishment. Он описывает способы обхода NAT, способы установки соединения, если у нас есть NAT.
Этот фреймворк использует приписывание так называемого STUN-сервера.
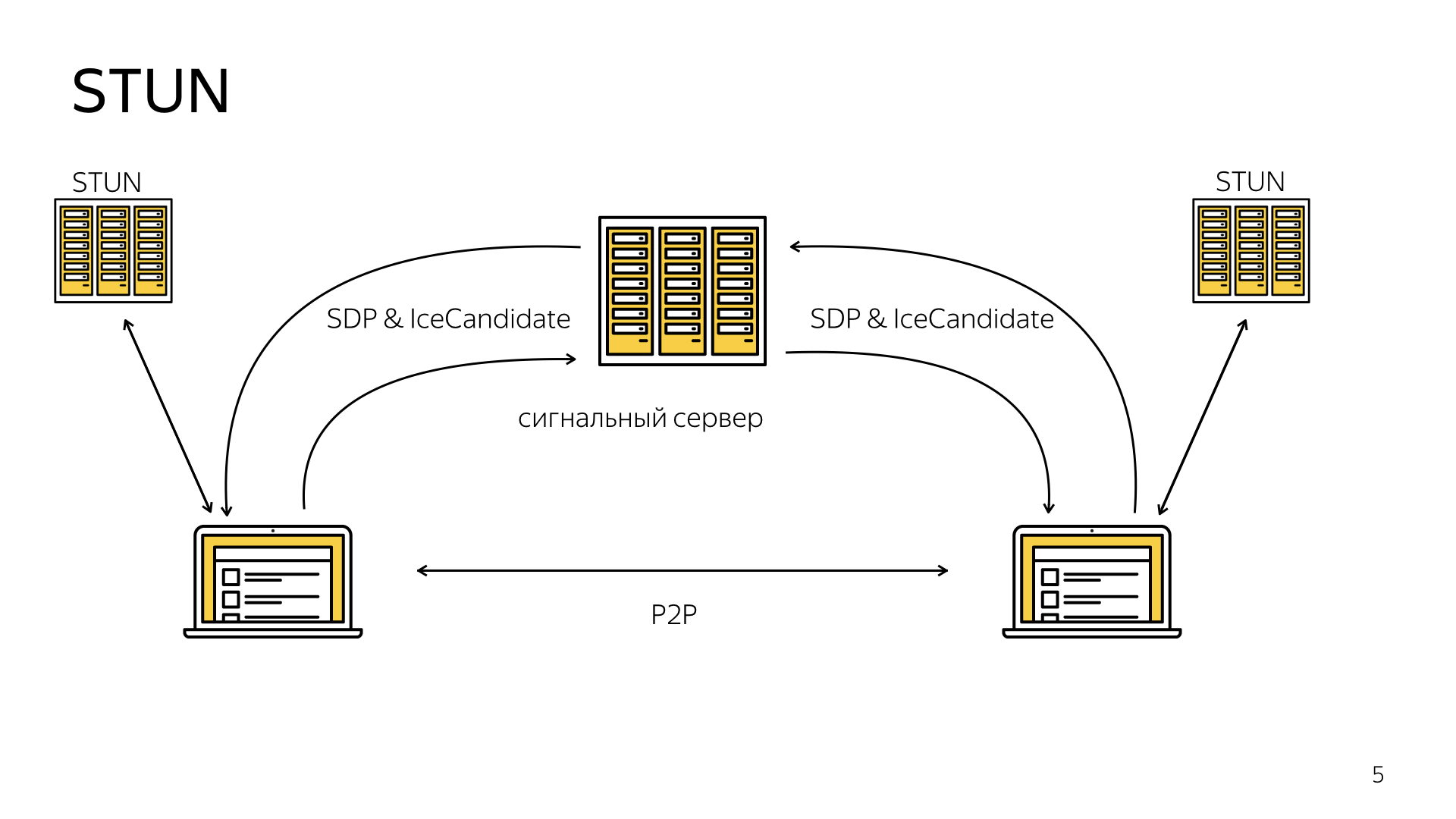
Это такой специальный сервер, обращаясь к которому, вы можете узнать свой внешний IP-адрес. Таким образом, в процессе установки P2P соединения, каждый из клиентов должен сделать по запросу к этому STUN-серверу, чтобы узнать свой IP-адрес, и сформировать дополнительную информацию, IceCandidate, и с помощью сигнального механизма также этим IceCandidate обменяться. Тогда клиенты будут знать друг о друге с правильными IP-адресами, и смогут установить P2P соединение.
Однако бывают более сложные случаи. Например, когда компьютер скрыт за двойным NAT. В этом случае фреймворк ICE предписывает использование TURN-сервера.
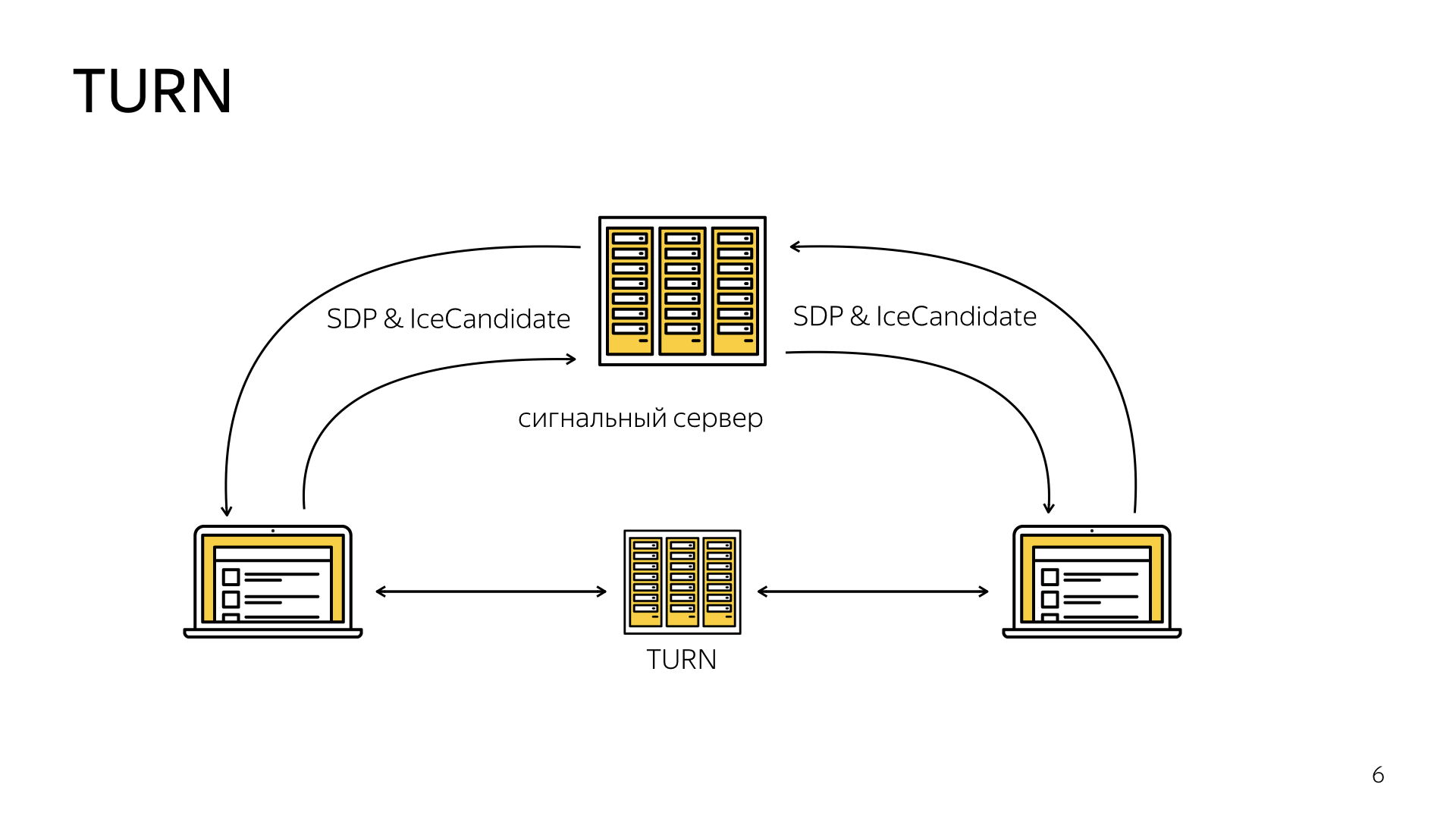
Это такой специальный сервер, который превращает соединение клиент-клиент, P2P, в соединение клиент-сервер-клиент, то есть выступает в роли ретранслятора. Хорошая новость для разработчиков в том, что независимо от того, по какому из трех сценариев пошла установка соединения, находимся ли мы в локальной сети, нужно ли обратиться к STUN- или TURN-серверу, АPI-технология для нас будет идентичной. Мы просто в начале указываем конфигурацию ICE- и TURN-серверов, указываем, как к ним обратиться, и после этого технология делает для нас все под капотом.

Небольшое резюме. Чтобы установить соединение, нужно выбрать и реализовать некий механизм сигнализации, некого посредника, который будет помогать нам пересылать метаинформацию. WebRTC даст нам всю необходимую мету для этого.
Нам предстоит побороться с NAT, это наш главный враг на этом этапе. Но чтобы его обойти, используем STUN-сервер, чтобы узнать свой внешний IP-адрес, и TURN-сервер используем в качестве ретранслятора.
Что же именно мы передаем? Про медиа-потоки.

Медиапотоки — это такие каналы, которые внутри себя содержат треки. Треки внутри медиа-потока синхронизированы. Аудио и видео не будет расходиться, они будут идти с единым таймингом. Вы можете внутри медиапотока сделать любое количество треков, треками можно управлять по отдельности, например, вы можете приглушить аудио, оставив только картинку. Также вы можете передавать любое количество медиа-потоков, что позволяет вам, например, реализовать конференцию.
Как же получить доступ к медиа из браузера? Поговорим про API.

Есть метод getUserMedia, который принимает на вход набор констрейнтов. Это специальный объект, где вы указываете, к каким именно устройствам вы хотите получить доступ, к какой именно камере, к какому микрофону. Указываете характеристики, которые хотите иметь, какое именно разрешение, и есть также два аргумента — successCallback и errorCallback, который вызывается в случае успеха или неудачи. В более современных реализациях технологии используются промисы.
Есть также удобный метод enumerateDevices, который возвращает список всех подключенных к вашему компьютеру медиа-устройств, что дает вам возможность показать их пользователю, нарисовать какой-то селектор, чтобы пользователь выбрал, какую конкретно камеру он хочет использовать.

Центральным объектом в API служит RTCPeerConnection. Когда мы выполняем соединение, то берем класс RTCPeerConnection, который возвращает объект peerConnection. В качестве конфигурации мы указываем набор ICE-серверов, то есть STUN- и TURN-серверов, к которым мы будем обращаться в процессе установки. И есть важный ивент onicecandidate, который триггерится каждый раз, когда нам нужна помощь нашего сигнального механизма. То есть технология WebRTC сделала запрос, например, к STUN-серверу, мы узнали свой внешний IP-адрес, появился новый сформированный ICECandidate, и нам нужно переслать его с помощью стороннего механизма, ивент стриггерился.

Когда мы устанавливаем соединение и хотим проинициализировать вызов, мы используем метод createOffer(), чтобы сформировать начальную SDP, offer SDP, ту самую мета-информацию, которую нужно переслать партнеру.
Чтобы установить ее в PeerConnection, мы используем метод setLocalDescription(). Собеседник получает эту информацию по сигнальному механизму, устанавливает ее себе с помощью метода setRemoteDescription() и формирует ответ с помощью метода createAnswer(), который также с помощью сигнального механизма пересылается первому клиенту.

Когда мы получили доступ к медиа, получили медиапоток, мы его передаем в наше P2P-соединение с помощью метода addStream, а наш собеседник узнает об этом, у него стриггерится ивент onaddstream. Он получит наш поток и сможет его отобразить.

Также вы можете работать с дата-потоками. Очень похоже на формирование обычного peerConnection, просто указываете RtpDataChannels: true и вызываете метод createDataChannel(). Подробно на этом останавливаться не буду, потому что такая работа очень похожа на работу с веб-сокетами.
Пару слов о безопасности. WebRTC работает только по HTTPS, ваш сайт должен быть подписан сертификатом. Медиапотоки тоже шифруются, используется DTLS. Технология не требует установки ничего дополнительного, никаких плагинов, и это хорошо. И не получится сделать шпионское приложение, сайт не будет подслушивать или подсматривать за пользователем, он покажет пользователю специальный промт, запросит у него доступ и получит его, только если пользователь разрешит доступ к аудио- и медиаустройствам.
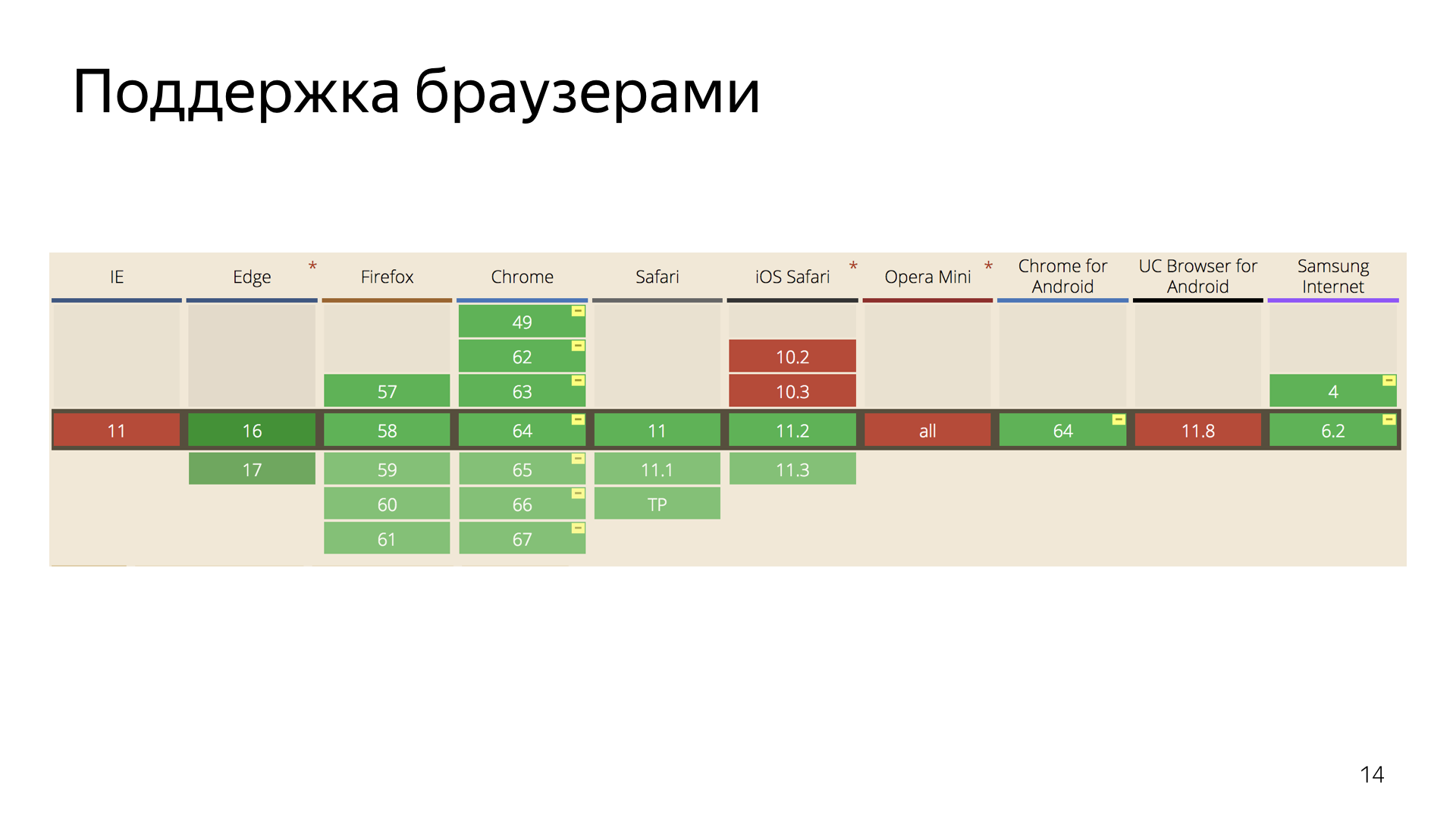
Что касается поддержки браузеров — IE остается и останется красным. В конце прошлого года добавилась поддержка Safari, то есть уже все современные браузеры умеют работать с этой технологией и мы можем смело ее использовать.
Хочу поделиться набором всяких полезностей, которые помогут вам, если вы желаете работать с WebRTC. В первую очередь это adapter. Технологии все время развиваются, и есть разница в браузерных API. Библиотека adapter нивелирует эту разницу и облегчает работу. Удобная библиотека для работы с дата-потоками — Peerjs. Также можете посмотреть на открытые реализации STUN- и TURN-сервера. Большой набор туториалов, примеров, статей находится на страничке awesome-webrtc, очень рекомендую.
Последняя незаменимая при дебаге полезность — webrtc-internals. Во время разработки вы можете в адресной строке набрать специальную команду — например, в браузере Chrome это Chrome://webrtc-internals. У вас откроется страница со всей информацией о вашем текущем WebRTC-соединении. Там будут и последовательности вызовов в методах, и все датаграммы, которыми обмениваются браузеры, и графики, которые каким-то характеризуют образом ваше соединение. В общем, там будет вся информация, которая понадобится при дебаге и разработке. Спасибо за внимание