Table of Contents
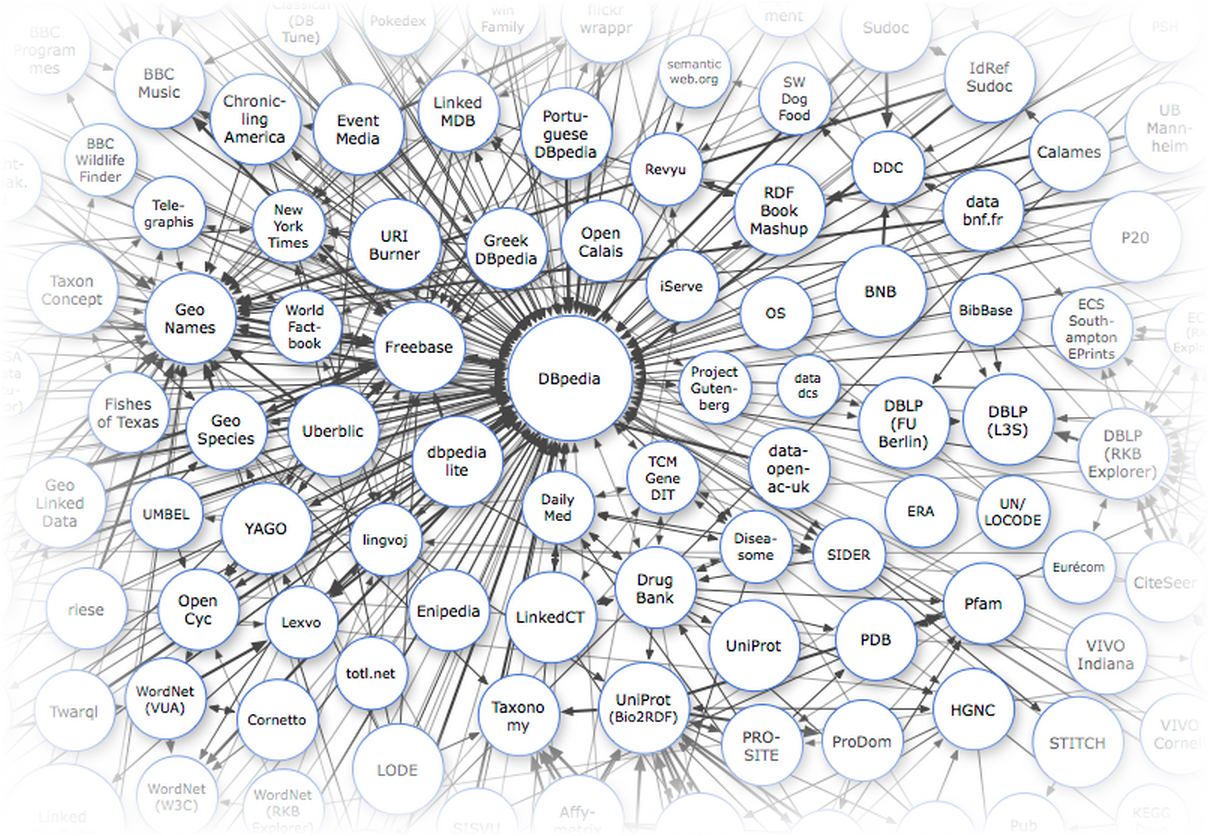
Одной из причин слабого использования Linked Data-баз знаний в обычных, ненаучных приложениях является то, что мы не привыкли придумывать юзкейсы, видя перед собой только данные. Трудно спорить с тем, что сейчас в России производится крайне мало взаимосвязанных данных. Однако это не значит, что разработчик, создающий приложение для русскоязычной аудитории совсем уж отрезан от мира семантического веба: кое-что всё-таки у нас есть.
Основными источниками данных для нас являются международные базы знаний, включающие русскоязычный контент: DBpedia, Freebase и Wikidata. В первую очередь это справочные, лингвистические и энциклопедические данные. Каждый раз когда вам в голову приходит мысль распарсить кусочек википедии или викисловаря — ущипните себя как следует и вспомните о том, что всё, что хранится в категориях, инфобоксах или таблицах, уже распарсено и доступно через API с помощью SPARQL или MQL-интерфейса.
Я попробую привести несколько примеров полезных энциклопедических данных, которые вы не найдете нигде, кроме Linked Data.
Городах, страны, исторические данные
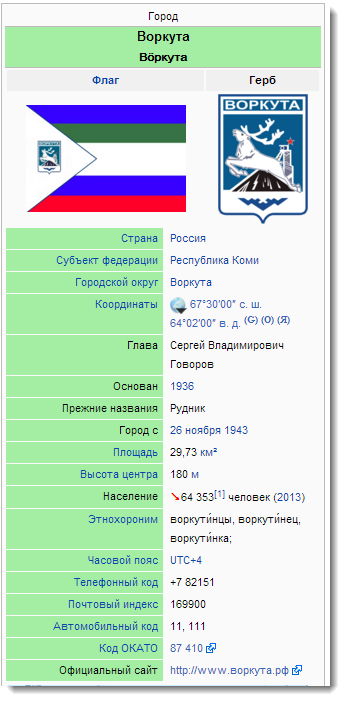 Если вас интересуют города и страны, то в Linked Data вы найдете не только информация об их местоположении (которую, если честно, лучше тащить из других источников), но также:
Если вас интересуют города и страны, то в Linked Data вы найдете не только информация об их местоположении (которую, если честно, лучше тащить из других источников), но также:
- достопримечательности вроде дворцов и памятников
- родившихся и умерших известных людей
- метеостатистику вроде месячного количества осадков и времени восхода солнца
- гербы, флаги
- демографию
- связанные исторические события
Обратите внимание, что когда мы здесь говорим, к примеру, о достопримечательностях, мы не имеем в виду жалкий список названий, упорядоченных по алфавиту. Все данные разбиты на категории, имеют привязку ко времени и месту, именам архитекторов, эпохам, художественным направлениям. Если вы наткнетесь на музей, вы сможете вытащить наиболее важные экспонаты, выставляемые в нем. Само собой, информация о людях-создателях этих экспонатов будет также доступна.
Как и везде в семантической паутине мы будем получать списки объектов, связанных с другими объектами и порой указывающими на альтернативные описания в других базах данных. Мне на ум сразу приходят туристические приложения: пользователю можно предоставить не просто возможность «посмотреть достопримечательности в районе Московского проспекта», но позволить ему отфильтровать только объекты, относящиеся к неоклассицизму первой четверти XX века. А если вы задействуете дерево категорий DBPedia, но можете предложить пользователю еще и связанные стили, например, ранний модерн.
Некоторые географические точки привязаны к событиям — про них тоже можно узнать довольно многое. Так например, довольно просто получить соотношение сил и количество убитых в Куликовской или Бородинской битвах. Разумеется, не забыты и персоналии, с которыми связаны события.
SELECT DISTINCT ?strength, ?result, ?longitute, ?latitude, ?commander WHERE {
dbpedia:Battle_of_Kulikovo dbpprop:strength ?strength;
dbpprop:result ?result;
geo:long ?longitute;
geo:lat ?latitude;
dbpedia-owl:commander ?commander
}
LIMIT 1000
Данные об институтах, организациях, госструктурах
Такого рода даты часто нужны в аналитике. Например для того, чтобы подсчитывать, какой вуз выпускает больше всего олигархов/ученых/писателей, достойных упоминания в Википедии.
- численность персонала/студентов/профессоров, для студентов — количество баков, магистров, иностранных студентов
- годовая выручка
- место в рейтингах
- даты основания
- дочерние и материнские компании
- информация о руководителях
Композиторы, музыканты, фильмы
Насчет фильмов все выглядит более чем крепко: Freebase, Dbpedia и Linkedmdb располагают очень и очень неплохими массивами данных на тему кинематографии.
ileriseviye.wordpress.com/2012/07/11/is-semantic-web-and-linked-data-good-enough-sparql-dbpedia-vs-python-imdbpy
Мы не только легко можем посмотреть, какой актер где снимался, в каком году вышел фильм и кто его выпустил, но еще и узнать, кто повлиял на актёра, когда он родился, что у него с семейным положением и занимается ли он чем-либо, кроме съемок.
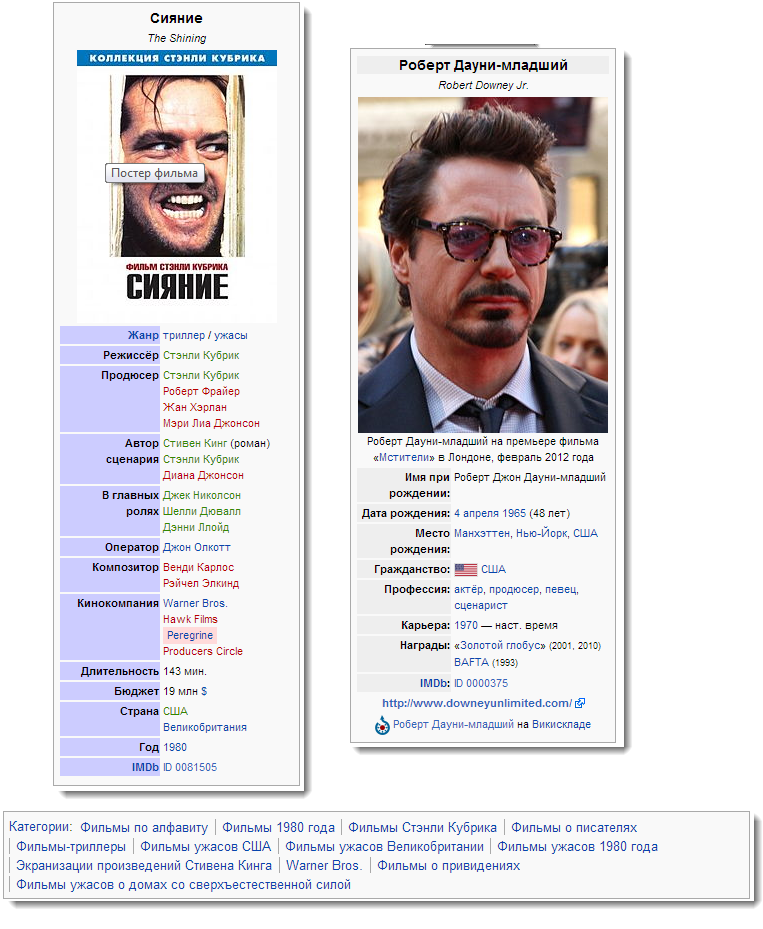
Например, вот этот запрос к Dbpedia выведет всех актеров, которые снимались и в фильме The Shining, и в фильме Hoffa:

Самым замечательным источником данных в области музыки, пожалуй, является MusicBrainz. Конечно же, он есть и в RDF, и конечно же, вы будете использовать традиционные API чтобы получить к ним доступ. Однако Freebase и Dbpedia могут пригодиться и тут — в последней есть, например, информация о гастролях музыкальных групп. Ну и даты рождения, влияние, стили и жанры — энциклопедические данные для музыки тоже присутствуют. Собственно в обучающих материалах Freebase используется как раз музыкальный пример: доставание данных о группе The Police:
{
"type" : "/music/album",
"name" : "Synchronicity",
"artist" : "The Police",
"track" : [{
"name":null,
"length":null
}]
}
Наверное, интересно было бы использовать это в связке с API Last.fm
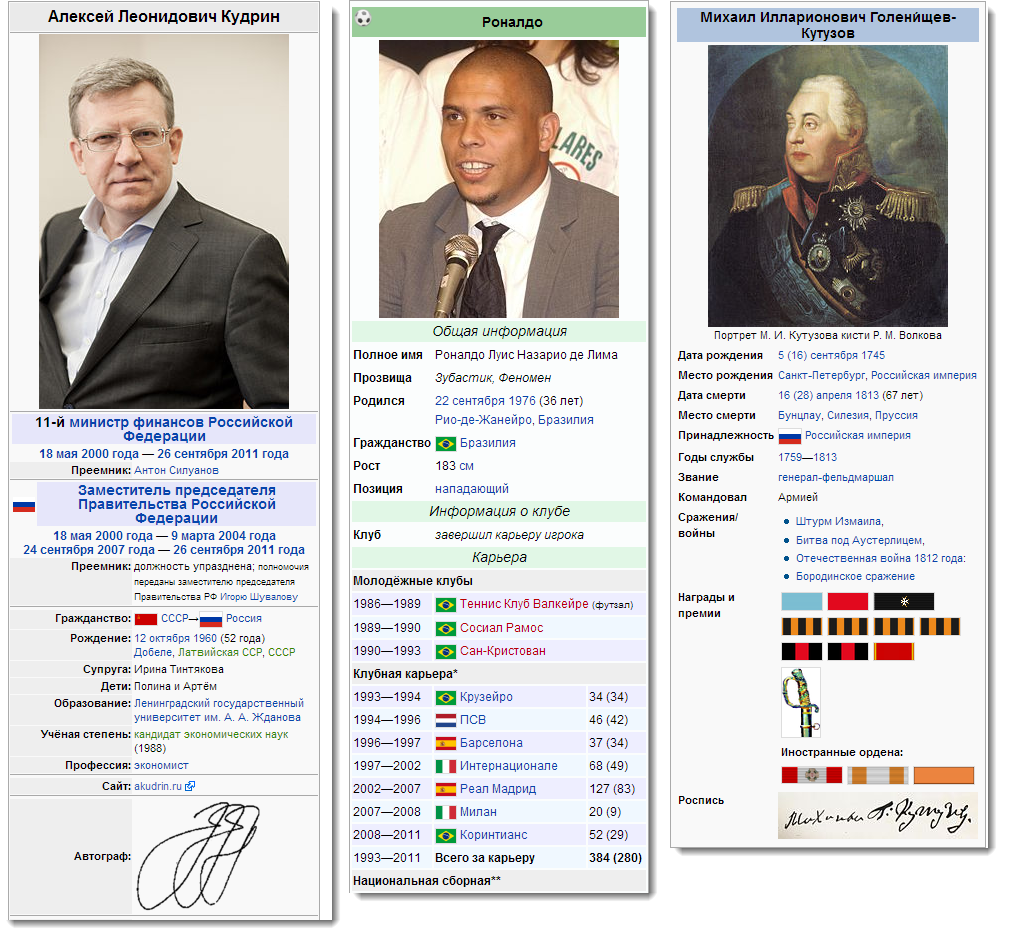
Персоналии: политики, спортсмены, исторические фигуры
При описании персоналий в википедиях информационные боксы используются довольно интенсивно — это придаёт статье строгий вид. Поэтому если вы социальный активист и пишете сайт с информацией о политиках — вы найдете в Dbpedia, кто где учился, какие награды имеет и какие должности занимал. Приложения, связанные со спортом могут использовать данные о карьере спортсмена, его рост, вес и важные факты биографии.
Лингвистические приложения. Иерархия категорий
Для нужд классификации и кластеризации, а также задач математической лингвистики часто нужны иерархии понятий. Например, что палец является разновидностью части тела. Semantic Web спешит на помощь и позволяет вам не парсить категории википедии, а доставать их готовыми из Dbpedia или www.mpi-inf.mpg.de/yago-naga YAGO. Если же размер иерархии для вас менее важен, чем её качество, вы можете поглядеть на созданные вручную онтологии Dbpedia, Cyc, Umbel.
Лингвистические приложения. Викисловарь и переводы
В конце 2012 года команда Dbpedia запустила проект Wiktionary — доступ к Викисловарю как к базе данных. Сейчас можно делать запросы к английскому, немецкому, французскому, русскому, греческому и вьетнамскому языкам. Давайте попробуем вытащить переводы для какого-нибудь хорошего русского слова через SPARQL-точку Wiktionary:

Среди Semantic Web энтузиастов немало лингвистов, а потому лингвистический мир имеет своё собственное облако взаимосвязанных данных.
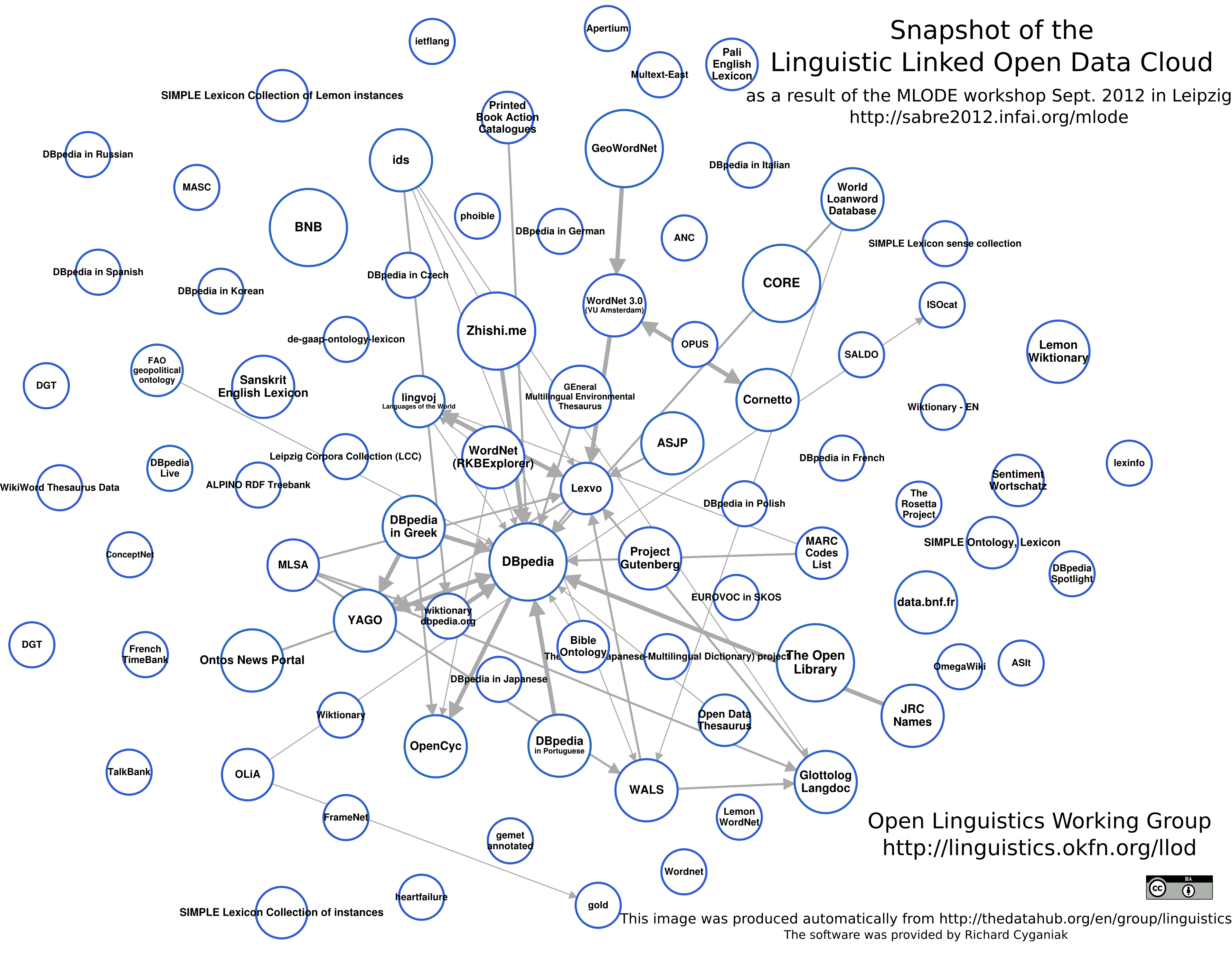
Много полезной информации по Linked и не-Linked данным можно получить c порталов Open Knowledge Foundation и нашего русского NLPub.
Как находить хорошие данные
Для Freebase на главной странице есть визуализация того, какие категории содержат наибольшее количество объектов.
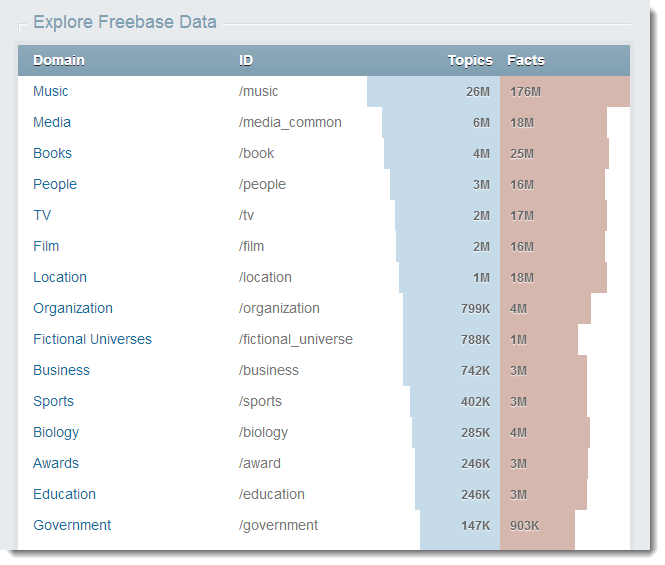
Для DBPedia простой способ понять, где скрываются качественные данные тоже есть. Надо обратиться к приложению Mappings.DBpedia и его статистической сводке.
Маппинги — это отличный инструмент, позволяющий пользователям DBpedia влиять на то, как работают парсеры. Я обязательно расскажу про них подробнеев последующих статьях, а пока ограничимся вот этой страницей:
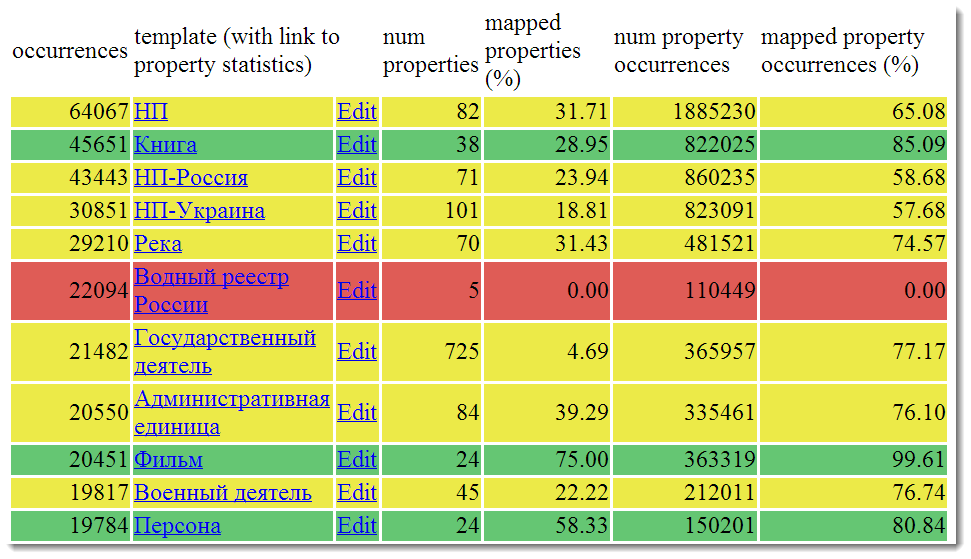
В ячейках написаны названия википедических шаблонов. Более красные ячейки содержат данные, распарсенные полностью автоматически, более зеленые указывают на то, что парсинг производился с участием людей, а потому качество данных должно быть выше.
Поиск
Ну а что тут сказать, поиск он и есть поиск. Мы используем движки Sig.ma, Sindice и Swoogle. Все они позволяют искать внутри одного датасета или же по всему множеству LInked Data.
Freebase: делаем запросы к Google Knowledge Graph
Больше года назад Google объявил, что отныне в их поиске используется таинственная Сеть Знаний (официальный перевод Knowledge Graph). Возможно, не все знают, что значительная часть данных Сети доступна для использования всеми желающими и доступна по прекрасно описанному API. Этой частью является база знаний Freebase, поддерживаемая Google и энтузиастами. В этой статье мы сначала немного подурачимся, а потом попробуем сделать несколько простеньких запросов на языке MQL.
Эта статья — вторая из цикла Базы знаний. Следите за обновлениями.
- Часть 1 — Введение
- Часть 2 — Freebase: делаем запросы к Google Knowledge Graph
- Часть 3 — Dbpedia — ядро мира Linked Data
- Часть 4 — Wikidata — семантическая википедия
Google Knowledge Graph с точки зрения рядового пользователя
Одним из видимых проявлений Google Knowledge Graph являются информационные панели, кратко описывающие тот объект, который вы ищете. Они часто возникают при поиске персоналий, чуть реже — географических наименований. Они чаще возникают для запросов, заданных на английском языке в английском интерфейсе, но мы будем придерживаться русского языка там, где это возможно.
Например, запрос Роджер Уотерс даёт следующий результат:
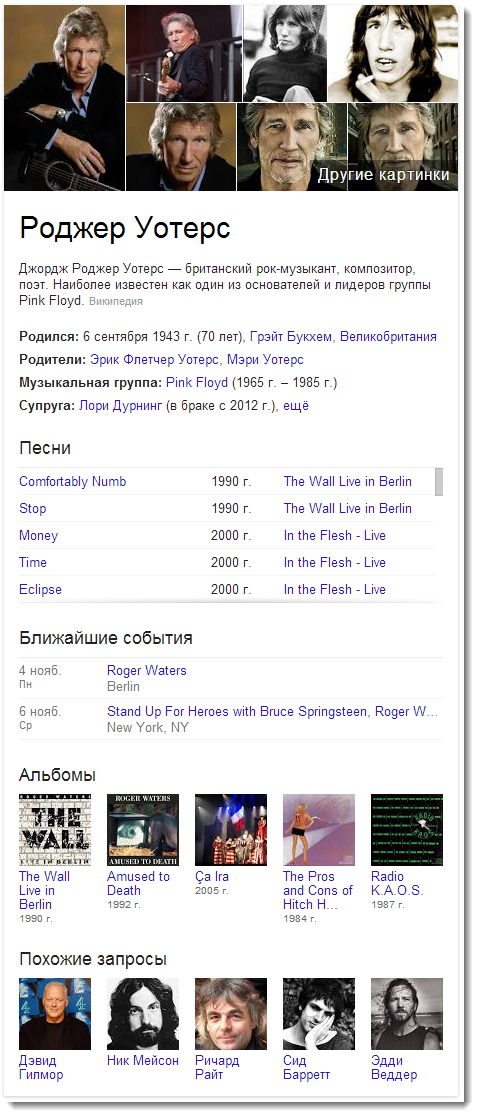
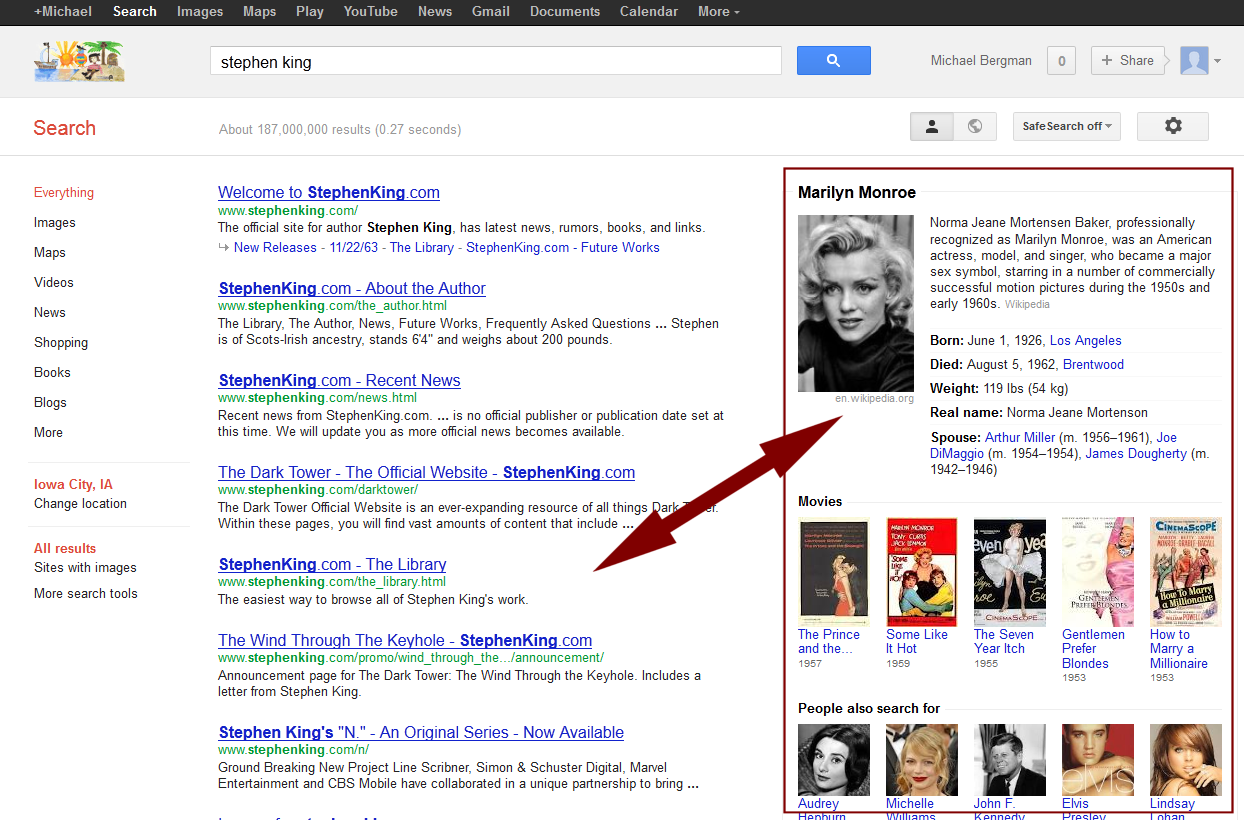
Покликайте по ссылкам в инфобоксе и обратите внимание на URL — в нем используется параметр stick, содержимым которого является некоторый идентификатор вида &stick=H4sIAAAAAAAAAONg[VuLQz9U3]<сам идентификатор>AAAA
Когда Knowledge Graph только появился, это позволяло демонстрировать непосвященным небольшую уличную магию, например, добавлять &stick-параметр от Мерилин Монро к запросу от Стивена Кинга:
Сейчас такую возможность прикрыли, да и ни к чему она нам — лучше посмотрим на что-нибудь полезное. К примеру, недавно появилась возможность сравнить несколько объектов с помощью ключевого слова vs:
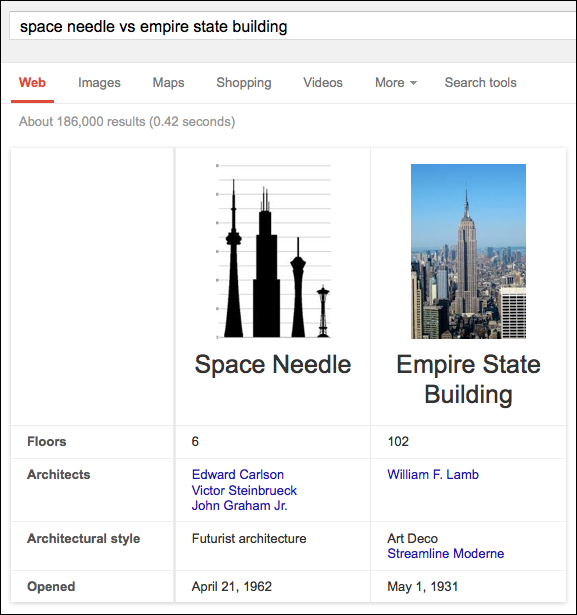
Гугл обещает добавить еще много вкусностей, связанных с умным поиском и ответами на вопросы, и Knowledge Graph будет одним из столпов, на котором эта интеллектуальность держится. Что особенно прекрасно для нас, так это то, что кусочек Knowledge Graph’a открыт для использования всеми желающими.
Freebase — подграф GNG
Начнем с исторического экскурса. Компания Metaweb начала работу над своей базой знаний в 2005 году. По способу наполнения данными Freebase больше всего походила на Dbpedia: львиную долю знаний, представленных во Freebase, являлись данные из Википедии. Отличием от Dbpedia была, во-первых, возможность поправлять введенные данные вручную, а во-вторых то, что Freebase не гнушалась и другими источниками данных. В отличии от команды DBpedia, представители Metaweb не слишком заботились о том, чтобы публиковать научные статьи (хотя в последнее время начали, вот тут интересный список), и признавались, что код основного компонента, graphd, вряд ли когда-нибудь увидит свет дня.
В 2010 году компания Metaweb была куплена Google, но, судя по рассылке Freebase, поисковый гигант не слишком вмешивался в дела свежеприобритенной команды. После выпуска красочного ролика, в котором Google рвет конкурентов, как пионерскую правду с помощью своих новых интеллектуальных семантических технологий, представители Metaweb (а затем и Google) подтвердили, что Freebase является очень важной частью Сети Знаний, наряду с Википедией и базой фактов ЦРУ. Во время большого субботника по унификации всех гугловых API, программный интерфейс Freebase сильным изменениям подвергать не стали, а его описание просто перенесли на developers.google.com. Для того, чтобы спросить что-нибудь у базы знаний мы по-прежнему используем язык запросов MQL (произн. «микл», Metaweb Query Language). За дело!
Первый запрос и редактор
Начнем с простенького вопроса: спросим у Freebase какой-нибудь факт, например дату рождения Леонардо да Винчи:
www.googleapis.com/freebase/v1/mqlread?query={"/type/object/id":"/en/leonardo_da_vinci","/people/person/date_of_birth":null}
Получим вполне корректный результат:
{
"result": {
"/type/object/id": "/en/leonardo_da_vinci",
"/people/person/date_of_birth": "1452-04-15"
}
}
Для того, чтобы нам было проще упражняться, мы будем использовать редактор запросов, любезно предоставляемый Freebase.
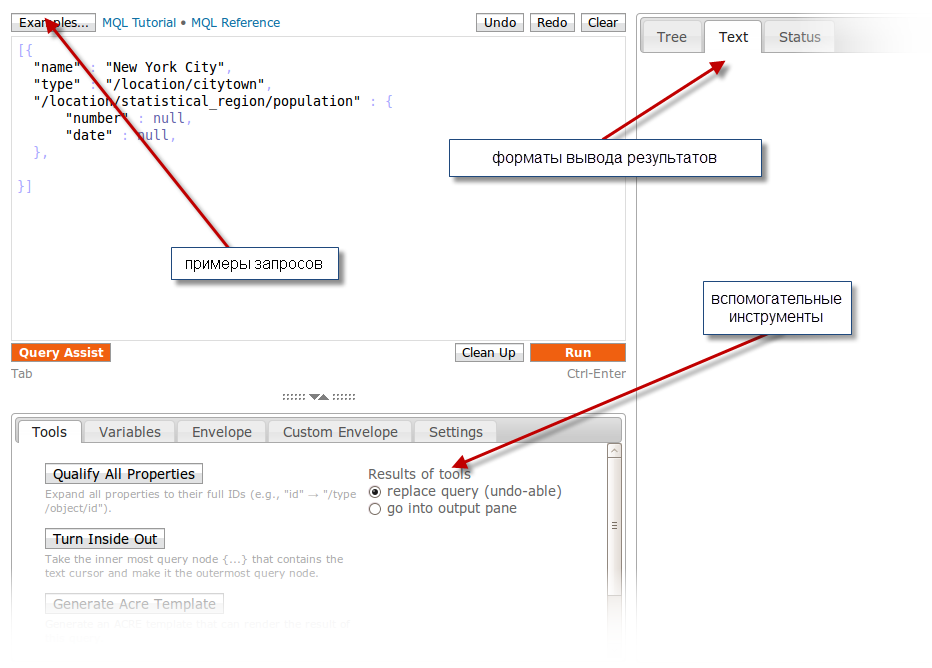
Редактор этот страшно удобен и имеет прекрасную функцию автодополнения запросов — в случае затруднений просто нажмите Ctrl+Enter и вы получите отличные контекстные подсказки. В нижней панели редактора расположились полезные инструменты, которые подробно описаны в руководстве. При самостоятельном изучении особенно советуем поглядеть на кнопку examples, содержащую примеры запросов, проясняющим многие возможности MQL.
Ну что, вот наш запрос, а вот ответ на него:
| Запрос | Ответ |
|---|---|
|
|
Разберем этот запрос подробнее. Мы указали идентификатор объекта во Freebase с помощью термина id. Идентификаторы есть у всех объектов, а слово id является сокращением от /type/object/id. Есть много других /type/object свойств, которыми обладают все сущности Freebase, они будут рассмотрены чуть позже.
Объект, имеющий идентификатор /en/leonardo_da_vinci, возможно, обладает свойством /people/person/date_of_birth, значения которого мы не знаем. Мы ставим вместо этого значения специальное слово null, на место которого в ответе Freebase запишет значение из базы.
Как легко заметить, запрос и ответ на него симметричны.
Сложный запрос
Теперь, для того, чтобы возникло побольше вопросов, мы составим достаточно сложный MQL-запрос и вкратце его объясним. После этого можно будет приступить к подробному изучению структуры Freebase и обзору возможностей языка.
Итак, вот наш запрос (взят из руководства по MQL):
| Запрос | Ответ |
|---|---|
|
|
Попробуем вкратце описать, что за средства MQL использованы в данном запросе.
Во-первых, как можно видеть, весь запрос обернут в конструкцию [ { } ], что означает, что в качестве результата вы ожидаете массив объектов, а не один объект, как в случае с { }.
Строки 2-4 не должны вызывать каких-либо проблем: мы ищем объект типа альбом (/music/album), нам хочется получить его имя и нас не интересуют альбомы, называющиеся “Greatest Hits“.
В строчках 5-8 и 11-15 появляется оператор ИЛИ |= — нас интересуют альбомы, у которых дата выхода равна 1978 или 1979 году. Перейдем теперь к жанру:
“genre”:[],
“a:genre”: “New Wave”,
“b:genre|=”: [
“Punk Rock”,
“Post-punk”,
“Progressive rock”
],
Первая строчка говорит о том, что нам хочется получить список жанров данных альбомов в ответе запроса. Для этого мы добавили в запрос пустой список [ ]. Дальше мы говорим, что нас интересуют только альбомы, в жанрах которых указаны New Wave И один из списка «Punk Rock», «Post-punk», «Progressive rock».
Наконец, строки 23-24 содержат директивы MQL: мне интересны только два результата (limit) и я хочу отсортировать их по имени (sort).
JSON в MQL
MQL-запросы и ответы на них являются JSON-объектами, поэтому для самых маленьких (или тех, кто не относится к веб-разработчикам) расскажу о JSON.
Не совсем JSON
Вообще, MQL-запросы не являются корректными JSON-объектами. MQL — это надмножество JSON и в нём разрешаются разного рода вольности. Одна из идей продуктов Metaweb заключается в том, что программы должны уметь прощать пользователям ошибки и описки, которые те делают. Эта идея есть и в других языках и программах, а в первую очередь — в World Wide Web — ничего страшного, что некоторые части html написаны с ошибками, нужно все равно постараться отобразить документ.
Вот, например, корректный JSON-запрос, ищущий людей с редкой и ценной профессией:
{
"id": "/en/pope",
"/people/profession/people_with_this_profession": [{
"name": null,
"limit": 4
}]
}Мы можем убрать кавычки и запрос продолжит работать:
{
id: /en/pope,
/people/profession/people_with_this_profession: [{
name: null,
limit: 4
}]
}Закрывать скобочки и разделять пары двоеточием тоже не обязательно, так что вот пример совсем уж безобразия:
id /en/pope
/people/profession/people_with_this_profession [{
name null
limit 4
Устройство Freebase
Официальное руководство дает очень хорошее введение в то, как хранятся данные внутри Freebase. Нам это не слишком важно, потому что используемые во Freebase четверки объектов полностью скрыты за объектной парадигмой. Если вам интересно, можете обратиться к соответствующей странице мануала
Итак, Freebase позволяет нам думать о том, что внутри него лежат объекты. Каждый объект ограничивается фигурными скобками { } и состоит из пар «свойство-значение», разделенных двоеточиями. Объекты, которые Freebase выдает в качестве ответов на MQL-запросы, являются корректными JSON-объектами, однако они не похожи на объекты парадигмы ООП. Лучше всего думать о них, как о неупорядоченных множествах пар.
В качестве свойства (то есть того, что стоит до двоеточия) в MQL могут стоять идентификаторы. В качестве значений могут быть идентификаторы, литералы, массивы и, наконец, вложенные объекты.Freebase имеет правила, по которым должны строиться идентификаторы. Идентификатор состоит из пространства имен и ключа, разделенных прямым слэшем /. Рассмотрим, например, идентификатор /people/person/date_of_birth — в нем date_of_birth является ключом, а /people/person — пространством имен.
Идентификаторы уникальны. Они не обязаны нести смысловой нагрузки, однако зачастую по идентификатору объекта легко понять, о чем идет речь.

Универсальные свойства объектов
Все объекты Freebase обладают следующими зарезервированными (универсальными свойствами):
- имя —
/type/object/name - ключ —
/type/object/key - идентификатор —
/type/object/id - тип (обычно больше одного) —
/type/object/type - время создания —
/type/object/timestamp - создатель —
/type/object/creator - режим доступа —
/type/object/permission - глобальный идентификатор —
/type/object/guid - машинный идентификатор —
/type/object/mid
Мы рассмотрим тут свойства, которые наиболее часто используются в MQL-запросах: имена, идентификаторы и типы.
Идентификаторы
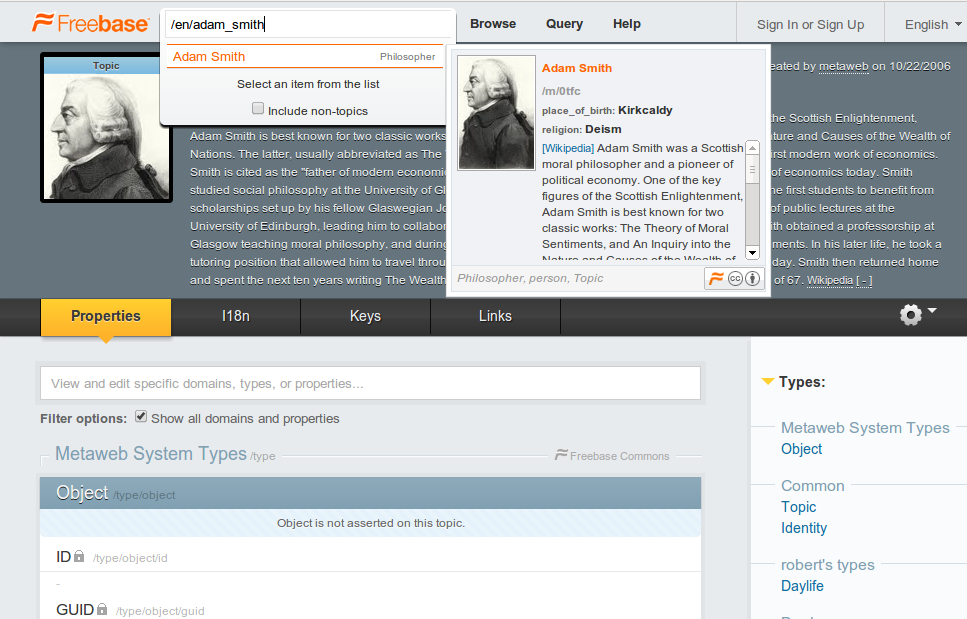
Во Freebase как-то очень много идентификаторов. Самый главный из них /type/object/guid, даётся раз и навсегда. Есть его сокращенная форма /type/object/mid. Ну а пользуются в запросах обычно /type/object/id — он часто бывает человекочитабельным. Самое главное, это то, что не бывает двух объектов с одинаковыми идентификаторами. Так например, взгляните, как многих людей звали Адам Смит (Adam Smith): статья на английской Википедии. Только моральный философ Адам Смит носит гордый идентификатор /en/adam_smith. Все остальные Адамы Смиты будут идентифицироваться по другому, будь они политиками (/en/adam_smith_1965), футболистами (/en/adam_smith_huddersfield) или кем-либо другим.
Вы можете ввести идентификатор в поле поиска на Freebase.com и получить страницу свойств объекта:
Свойство /type/object/name
У каждого объекта есть имя. Имя — вещь не уникальная, у объекта обычно несколько имен — по одному на каждый язык. Самое интересное, что это нисколько не усложняет запросы — вы заметите, что при запросе имен вам будет выдаваться только имя на языке, установленном во Freebase как текущий. Так что можно обращаться с объектами типа name как с обычными строками.
Свойство /type/object/type
Это свойство задает тип объекта. У одного объекта может быть несколько типов — обычно так и бывает.
Если в запросе вы указали свойство type, то вы пространство имен для этого типа можно опускать. Какие свойства относятся к типу /film/director? Разумеется, те, которые находятся в пространстве имен этого типа, то есть те, что начинаются с /film/director. Рассмотрим, например, запрос всех фильмов, снятых Стэнли Кубриком. Слева показан запрос в сокращенной форме, которой мы и будем пользоваться дальше, а справа — то, как он мог бы выглядеть, не будь разработчики Metaweb так добры к нам.
| Запрос | Запрос в полной форме |
|---|---|
|
|
Во-вторых, все свойства из пространства имен /type/object можно опускать — именно поэтому мы имеет право писать просто id, name, type и т.д. Почему? Потому что все объекты в Freebase имеют тип Объект.
Различные виды MQL-запросов
Мы уже разобрали довольно много запросов, но пока не сосредотачивались на самом языке. В первую очередь, давайте посмотрим на то, как в MQL запрашиваются нужные значения. Бывают следующие случаи:
- мне нужно запросить одно литеральное значение. Например, дату рождения человека
- мне нужно запросить массив значений. Например список альбомов музыкальной группы.
- мне нужно запросить один объект c его основными свойствами: идентификатором, основным типом и именем
- мне нужно запросить массив объектов
- мне нужно узнать всё об объекте
Запрос одного значения
Если вы хотите, чтобы Freebase вернул вам объект той же структуры, что и объект запроса, но с заполненным неизвестным полем, то в запросе надо вместо этого поля подставить null. Мы видели довольно много таких примеров, вот вам еще один. Спросим у музыканта Кита Эмерсона, откуда он родом:
| Запрос | Ответ |
|---|---|
|
|
Запрос массива значений
Если мы попробуем использовать null для запроса всех альбомов музыкальной группы, то мы получим ошибку. Если вы ожидаете массив объектов, используйте квадратные скобки []. Freebase заполнит этот массив строками, перечисленными через запятую. Примеров с альбомами музкалььных групп полно и в официальном руководстве, а мы найдем список книжек, написанных Хокингом:
| Запрос | Ответ |
|---|---|
|
Там еще много
|
Если вы напротив, запросите массив вместо одиночного значения – в этот нет никаких проблем – Freebase преобразует результаты и выдаст массив с одним-единственным значением.
Запрос объектов
Хорошо, но для моего приложения мне интересно знать не только названия книжек Хокинга, но и даты их выхода, и картиночки бы не помешали! Такое тоже возможно. Дело в том, что массив книг, который мы получили в прошлом запросе, только выглядит массивом строк. На самом деле, это массив объектов, просто Freebase сворачивает объекты в строки, оставляя только их свойство name.
Также и Англия, откуда родом наш музыкант, это не просто строка «England», а полноценный объект. Чтобы получить объектное представление в запросе, используется конструкция { }, вот так:
{
"name": "Keith Emerson",
"type": "/music/artist",
"origin": { }
}
В результате нам выдадут самую важную информацию об объекте: его идентификатор, название и список типов:
Вложенные запросы
Можно получить любую другую информацию о стране происхождения нашего музыканта, формируя, таким образом, вложенный запрос. Например, мне хочется узнать, на каком языке говорят в стране, откуда родом Эмерсон. Обратите внимание, я добавляю тип для страны, чтобы получать подсказки от редактора запросов:
| Запрос | Ответ |
|---|---|
|
|
Можно спуститься ниже: к какой языковой семье относится язык, на котором говорят в стране, откуда родом Эмерсон?
| Запрос | Ответ |
|---|---|
|
|
Эти довольно дурацкие запросы легко обобщаются в нечто более полезное. Например, запрос на получение списка музыкантов, родом из англоговорящих стран. Обратите внимание, что я часто использую вывод в виде массива. Ну и еще на слово limit, которое ограничивает вывод тремя результатами:
| Запрос | Ответ |
|---|---|
|
|
Запрос всех свойств объекта
Полезная вещь при конструировании запроса — получить все свойства объекта. Конструкция, используемая для этого очень проста и удобна: звездочка в качестве названия свойства и пустой массив, который заполнится значениями "*" : []
| Запрос | Ответ |
|---|---|
|
У Англии много свойств
|
Как лучше запрашивать объекты
Для тех, кто успел запутаться в скобочках, вот сводка по тому, как во Freebase можно запрашивать объекты:
| Конструкция | Её смысл |
|---|---|
|
запрашивается значение свойства в виде одной строка. В качетсве этой строки будет выдано значение default-свойства объекта: value (для литералов) или name (для объектов). Если значением свойства является массив, выдается ошибка! |
|
запрашивается массив строк. Результатом может быть пустой, массив, массив с одним значением или массив с несколькими значениями |
|
на каждое свойство объекта запрашивается массив его значений |
|
запрашивается краткая информация об объекте. Для обычных объектов выдается их имя, идентификатор и тип |
|
запрашивается массив объектов в кратком виде. Работает аналогично {}, но для массивов |
|
у объекта-значения свойства спрашивается все, что указано в запросе |
|
вложенный запрос относится ко всем объектам в массиве значений свойств. Действует аналогично предыдущему для массивов. |
Для начала достаточно. Понятное дело, что в MQL есть различные компараторы, регулярные выражения, всякие там И, ИЛИ и НЕ. Еще прекрасен язык Acre, который позволяет форматировать результаты запросов подобно тому, как это делается в Semantic MediaWiki. Ну и впереди рассказ о Dbpedia и Wikidata. Что бы вам было интересно почитать в первую очередь?