
Table of Contents
Если вам интересно, как можно автоматизировать повседневные задачи разработчиков и построить удобную систему оркестрирования зависимостей ваших сервисов, загляните под кат. Об этом в своем докладе на конференции Golang Live 2020 рассказал разработчик продуктовой команды «Авито» – Auto B2B Иван Королев. Он затронул тему платформенных решений для создания микросервисов и на живом примере продемонстрировал, как происходит создание и развитие микросервиса в «Авито».
Что такое Platform as a Service, и зачем она нужна?
Платформа снижает overhead на интеграцию с разными инфраструктурными частями, будь то базы данных или сервис по сбору логов и метрик. Если платформы в компании нет, то каждая продуктовая команда вынуждена заниматься этим вопросом самостоятельно. В лучшем случае решением могут стать библиотеки. В худшем — свои костыли и велосипеды в каждом сервисе.
Платформа позволяет централизованно внедрять новые технологии в компании, опробовав их на не очень значимых для бизнеса сервисах и сформировав best practices. После этого она предлагает решать задачи единообразно.
Лучшие практики формируются не только по архитектурным решениям, но и по написанию кода и использованию отдельных библиотек.
Как в «Авито» появился PaaS
Рассмотрим инструменты инженеров «Авито» четыре года назад. Компания начинала с большого количества разных инструментов как для разработки, так и для эксплуатации. И инженеры работали со всем, что используется под капотом в любой облачной системе, будь то Kubernetes, сборка логов, ingress-контроллеры, шина данных для обмена асинхронными сообщениями.
В итоге самая большая сложность была в том, чтобы пригласить в продуктовые команды людей, которые знакомы хотя бы с частью этих инструментов. Иначе порог входа получался слишком высоким, и приходилось очень долго обучать новых сотрудников.
Три года назад мы использовали ванильный Kubernetes. И разработчики, получив определенные права на staging и на production, фактически выполняли роли системных администраторов. Они не только разрабатывали сервис, но и деплоили его, следили за ним, читали логи.
Конечно же, были шаблонные пайплайны для CI, которые упрощают выкатку. Не приходилось набирать команду в kubectl для выкатки руками. Но мы все равно использовали такие относительно низкоуровневые интерфейсы как kubectl. Позже появились helm-чарты, которые упрощают доставку сервиса, как набора Kubernetes-манифестов.
К чему мы пришли в итоге? Придумали штуку, которая называется PaaS и состоит из двух частей. Первая — это консольная утилита, благодаря которой можно совершать все необходимые с сервисом, начиная от его создания, заканчивая доведением до продакшена, просмотром логов, разворачиванием в локальном окружении. Вторая часть — PaaS dashboard.
Это графический интерфейс, который частично дублирует консольную утилиту, но предоставляет определенные удобства.
Все детали, вся подкапотная реализация скрыта от разработчиков за этими двумя интерфейсными штуками.
Какова же концепция PaaS? Максимально автоматизировать все, что можно автоматизировать, сокращая overhead на ручные действия продуктовых команд разработки. Бэклог PaaS основан на реальных потребностях инженеров, которые сформировались годами боли и крови. Помимо этого можно проводить опросы о том, что людям более приоритетно, а что менее. Таким образом к платформе можно относиться как к продукту, в котором решения принимаются на основе данных. Именно так формируется бэклог и roadmap развития.
Конечно же, у PaaS должен быть низкий порог входа. Благодаря этому разработчики концентрируются непосредственно на решении своих продуктовых задач, на продуктовой архитектуре, на архитектуре сервисов, а не на всем, что лежит под капотом.
В идеале нужно обеспечить нулевой overhead на интеграцию с инфраструктурой. Например, настройку подключений к базе данных (включая секреты), к кэшам, интеграцию в систему доставки логов. Хочется, чтобы разработчики не задумывались об этих вещах. Это не всегда получается, но к этому нужно стремиться, что реально при помощи PaaS.
Как это выглядит для пользователя?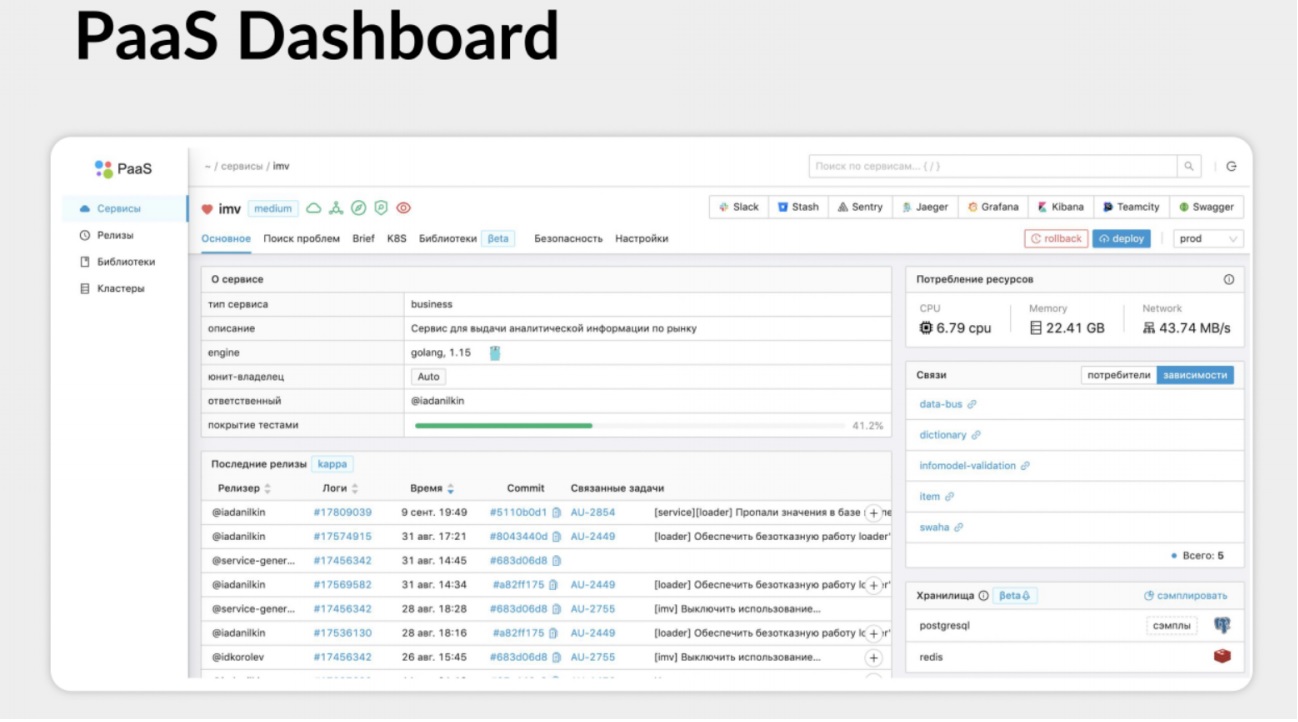
У нас есть консольная утилита и PaaS-dashboard, в котором можно получить информацию о том, что делает конкретный сервис, какие технологии использует под капотом, на каком языке написан, кто ответственный, насколько сервис покрыт тестами, когда был последний деплой. То есть это дашборд состояния сервиса с нужными ссылками на Grafana, Jaeger, репозиторий.
Кроме того есть сводная информация для быстрого поиска проблем.
Можно понять, как сервис в целом себя чувствовал, почему он деградировал (была какая-то зависимость, или дело в железе, а может быть, в базе данных?).
За прошедшее время все больные места, которые находили в команде архитектуры, выглядели разнообразно. Особенно когда кто-то вместо решения продуктовых задач половину спринта тратил на то, чтобы развернуть сервис и PG Bouncer, настроить подключение к БД, связать все сервисы воедино. Таких проблем может быть очень-очень много.
В первую очередь мы идем от проблем к решениям. И я именно так буду рассматривать дальше весь жизненный цикл создания сервиса. Сначала мы будем обсуждать, что у нас болело, а потом — к чему мы пришли, чтобы сделать жизнь разработчиков лучше.
Жизненный цикл сервиса довольно очевиден. Мы должны его создать. Затем его нужно протестировать, задеплоить в продакшн, и дальше успешно эксплуатировать.
Что требуется для создания сервиса
Для этого требуется создать репозиторий, зарегистрировать сервис в системе учета, описав, что это за сервис, какие у него функции, насколько он критичен, и так далее. И создать пачку ресурсов, разнообразные дашборды, завести пайплайны в CI, проект в Sentry. Разных систем может быть с десяток.
Кажется, это занимает лишь около часа. Но можно забыть создать какой-то ресурс, сделать это неправильно, узнать об этом через час, через два, через день, или только в продакшене. Чтобы избежать потенциальных проблем, хочется автоматизировать создание сервиса.
Для этого у нас есть утилита Avito Service Create, которая проводит разработчика по шагам, где он выбирает шаблон, а также указывает название, описание сервиса, тип:
В итоге мы получаем успешно созданный сервис, клонированный из определенного boiler plate репозитория, с заведенными проектами в TeamCity, Sentry и Grafana. Разработчик может этот сервис моментально задеплоить.
В результате, мы получаем:
Все это происходит под капотом, разработчику об этом не нужно думать.
Разработка сервиса с использованием PaaS
Главное, что болит при разработке без PaaS — это отсутствие унификации. Сервисы у разных команд получаются разные, даже если они используют одинаковые подходы к проектированию. Это вызывает ряд проблем, когда хочешь прийти в другую команду и сделать им pull request. Для этого надо сначала разобраться, как устроен сервис другой команды, как он деплоится, как тестируется – пройти весь спектр проблем новичка. Унификация позволила бы снять этот overhead на первичный вход.
Соответственно, метрики, логи, трейсы тоже могут писаться по-разному, и где искать их непонятно. А пока этого не узнаешь, сервис не задеплоишь. Интерфейсы взаимодействия сервиса могут быть не похожи с разными инфраструктурными частями. Например, у Kafka может быть несколько разных библиотек. Какая используется в сервисе? Кто знает.
В итоге получаем, что вход новых разработчиков сильно замедляется. Кроме того, сервис будет проблематично передать другой команде, если вдруг возникает такая потребность.
Что мы сделали, чтобы решить эту проблему? Договорились о единой структуре проектов для каждой технологии. Таким образом, переходя в другую команду, сотрудники примерно знают, как будет устроен проект. У сервисов есть базовые метрики и дашборды, логи в едином формате.
Кроме того, PaaS предоставляет единый RPC-протокол межсервисного взаимодействия. То есть разработчикам продуктовых команд не нужно изобретать свой собственный транспорт и думать, как интегрировать сервисы между собой.
Перейдем к конфигурации сервисов. Вначале у нас был Kubernetes и, соответственно, его чистые манифесты. Потом завезли helm-чарты, которые немножко упростили конфигурацию. Тем не менее, каждая продуктовая команда была вынуждена самостоятельно писать и поддерживать helm-чарты, и вообще иметь знания о том, как это должно быть устроено. Интересоваться best practices, натыкаться на одни и те же ошибки, даже несмотря на наличие документации.
В итоге мы получаем 40 килобайт манифестов в helm-директории каждого сервиса. При этом diff между этими манифестами в разных сервисах – это, по сути, несколько строк. Люди копировали их из шаблона, заменяли нужные строки, и получался чистый копипаст между разными сервисами. И конечно же, они могли ошибиться в простыне yaml.
В итоге мы пришли к единому конфигурационному файлу, который называется app.toml и лежит в корне каждого проекта. Он представляет из себя именно те части сервиса, которые могут меняться: название, описание, движок под капотом, настройки для выкатки (например, CPU, память, количество реплик в разных окружениях):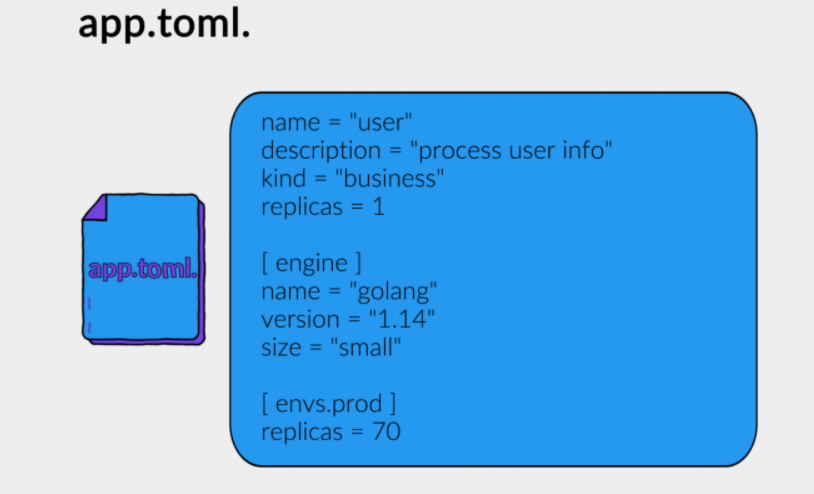
Таким образом мы выносим в конфигурацию только то, что нужно изменять.
И у нас есть единый файл конфигурации с плоской структурой, в отличие от YAML.
Главная проблема в helm-чертах – то, что они очень многословные. Приходится сидеть с линейкой и измерять, правильно ли сделан отступ у этой команды, иначе все сломается и не будет работать. TOML позволяет решить эту проблему.
Кроме того, сервисы конфигурируются через Environment-переменные, и их значение тоже хранятся в app.toml
Какие были проблемы с управлением секретами? Мы выбрали vault для хранения. Чтобы корректно его настроить, разработчику нужно понимать особенности его работы.
Нужно помнить о развесистой древовидной структуре ключей. UI далеко не самый удобный: в нем нет возможности просто прийти в корень и сходить к нужному ключу. Все ограничено правами доступа, и нужно точно знать путь с ключами сервиса, которые нужно поменять. Казалось бы ничего сложного, но это действие тоже требует когнитивной нагрузки.
Кроме того, нужно сделать интеграцию в helm-чартах, чтобы поднялись init-контейнеры, которые пойдут в vault и сформируют конфигурацию для pod’ов.
И все это может упасть в самый неожиданный момент именно в продакшене.
Казалось бы, секреты – та же самая часть конфигурации. Зачем сервису вообще знать, что за обычными конфигами надо идти в Env-переменные, а за «секретными» — в vault? Это все можно объединить.
Мы изменяем секреты непосредственно в PaaS dashboard. Они раскатываются на namespace. Таким образом мы можем изолировать сервисы от друг друга. А сами сервисы получают секреты из переменных окружения, нам в этом помогает небольшой бинарник, который на старте контейнера сходит в vault и положит конфигурацию в Environment.
По межсервисному взаимодействию тоже есть большая боль.
Если его не унифицировать, то для каждого сервиса нужно писать клиент, возможно даже на двух-трех языках. Нужно не забыть обработать ошибки и подключить общие библиотеки, например, Circuit breaker. А еще необходимо прокинуть все хэдеры, которые нужны для межсервисного взаимодействия, например, для аутентификации.
И совсем космическая штука: выставить таймауты так, чтобы они укладывались в NFR сервиса. Простой пример: сервис, который на каждый hit ходит в базу данных, отвечает по секунде, и кто-то ходит в него с таймаутом в 200 мс. Такие штуки хочется отслеживать и настраивать адекватно.
К чему мы пришли в PaaS? У нас есть контракт в едином описании как для клиента, так и сервера. По этому описанию автоматически генерируется код. И уже в этом автосгенерированном коде (по сути, клиентской библиотеке или серверной) заложены все паттерны взаимодействия микросервисов. Там подключаются трейсинг, метрики и прочее.
Как это выглядит? У нас собственный формат описания. Он является подмножеством Protobuf или Thrift.
В итоге мы описываем сервис, RPC-ручки, DTO на входе и на выходе. Типы данных: скаляры, вложенные структуры, массивы, key-value.
Файл описывает как серверную часть, по которой генерирует серверный код, так и клиентскую. Клиенты, подключая тот или иной сервис, переносят, копируют себе используемые методы и поля в сообщениях, и непосредственно в их репозитории генерируется клиентский год.
Кроме того, есть возможность указать, что поле необязательное. Эти поля можно деприкейтить, переводить в статус необязательных. А после, когда все сервисы у себя использование поля выпилили, удалить это поле и в серверном описании.
Таким образом, из единого файла описания мы генерируем код для разных языков, и проблем с клиентскими библиотеками уже не возникает.
Кроме того, подключены метрики и Circuit breaker, единообразным образом настраиваются таймауты, передается контекст запроса, и вся микросервисная структура работает правильно.
Синхронное взаимодействие построено на внутреннем RPC протоколе, со стороны разработчика практически нет доступа к подробностям реализации. Ему неважно, каким образом на уровне транспорта у нас передаются данные: это JSON, или Protobuf, или Msgpack. Команда архитектуры таким образом развязывает себе руки на будущее, и может безболезненно внедрить новые протоколы, если это необходимо.
И в автогенерированных клиентах уже есть все, что нужно для работы. Подключение библиотек явное и единообразное. И переходя с задачами из сервиса в сервис, ты знаешь, как с этим работать.
Асинхронное взаимодействие у нас также построено поверх нашего протокола. Аналогично описывается формат взаимодействия: какие события этот сервис порождают, и какие события другого сервиса он потребляет.
Под капотом есть общий сервис data-bus, который инкапсулирует работу с Kafka. Все сервисы взаимодействуют уже непосредственно с ним.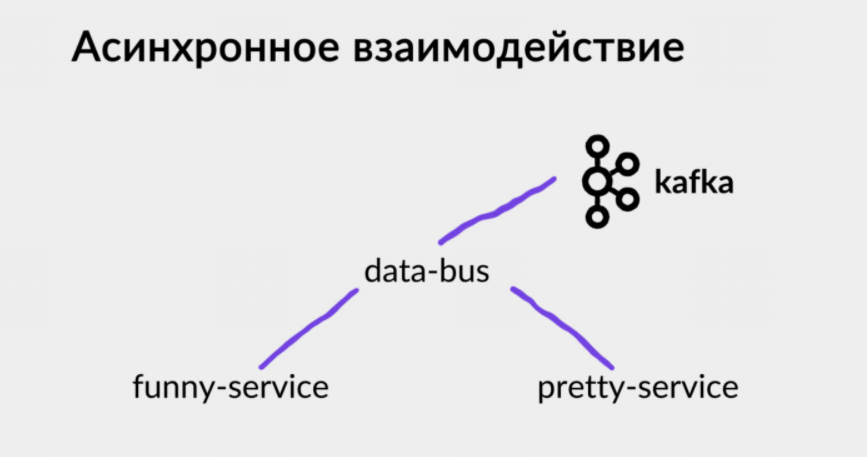
Таким образом, собственный язык описания нам дает единый формат всей межсервисной коммуникации. При этом, синтаксис близок к Go, имеет простую структуру без импортов, и под капотом даже используется lexer, встроенный в Go.
Отсутствие vendor-lock позволяет использовать любой удобный протокол под капотом, и закрывает разработчиков от возможных проблем несовместимых изменений, как это бывает с Protobuf.
При этом, есть возможность накрутить разнообразную валидацию. Например, не дать задеплоить сервис в продакшен, если клиенты все еще используют какое-то поле или метод, который удалили.
Хранилища данных также подключаются через утилиту avito в 1 клик. Это дает разработчикам стандартные подходы к миграциям, прозрачную интеграцию сервиса с инфраструктурой и деплой хранилища в Kubernetes для удобства локальной разработки.
Выглядит это просто: мы выбираем хранилище, например Postgres, вводим одну команду, и зависимость добавляется в app.toml: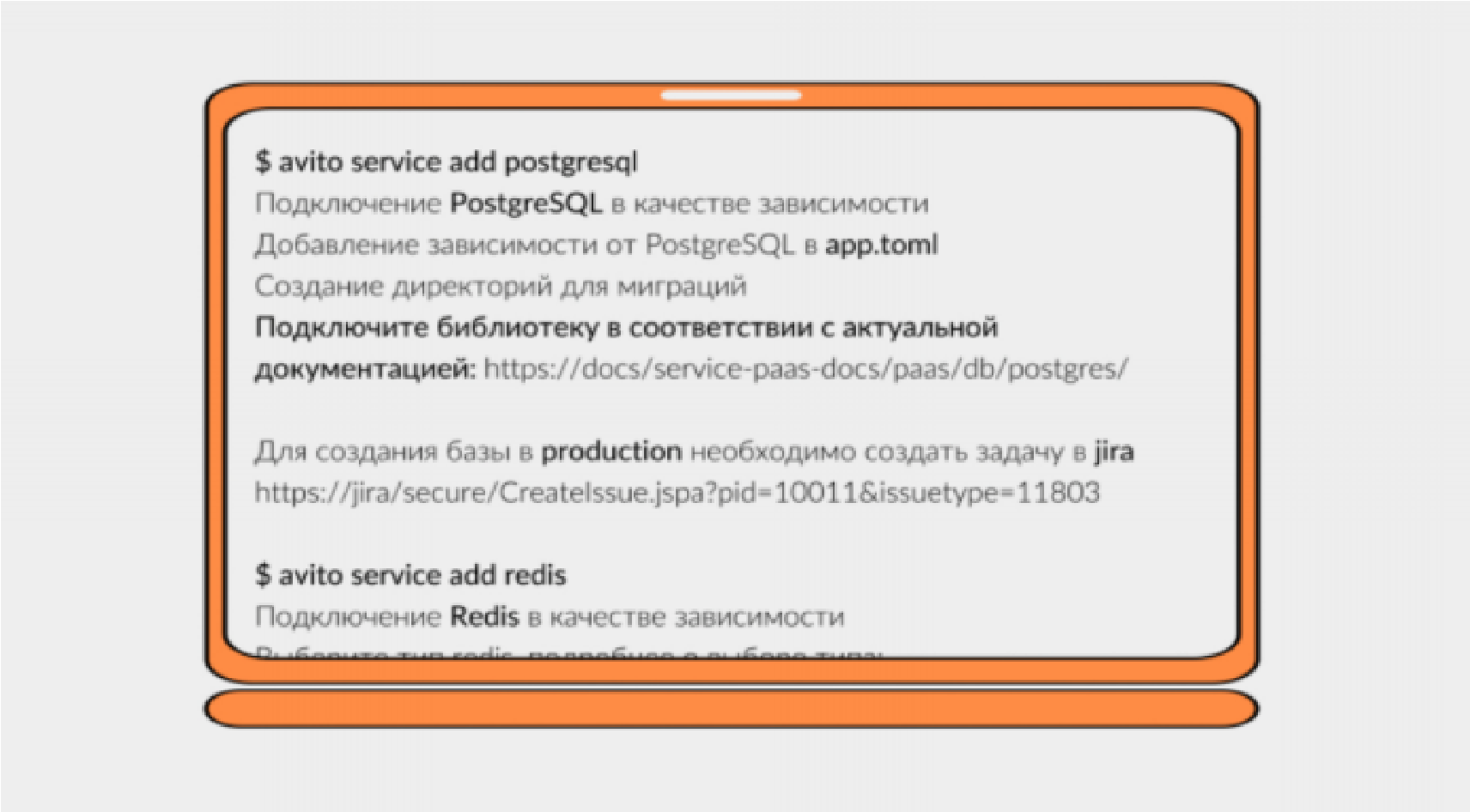
Подобным образом подключается Redis: мы выбираем тип хранилища: кэширующий в Kubernetes, c бекапами или без, шардированный вне Kubernetes. Зависимость от Redis также добавляется в app.toml, и дается рекомендация по подключению библиотеки к сервису.
Так описание хранилищ выглядит в app.toml: указывается тип хранилища, его размер, используемую версию. По этим данным генерятся манифесты для helm чарта: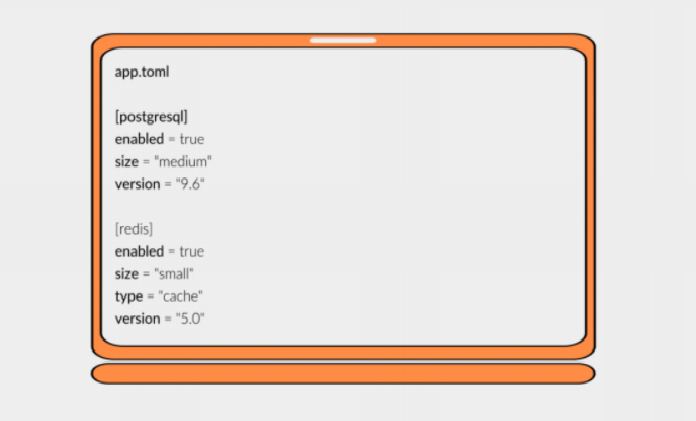
И самое главное — такое описание позволяет упростить локальную разработку.
К другим сервисам, от которых мы зависим, идем в стейджинг. Локальные хранилища деплоятся в minikube, включая локальную шину данных. А конфигурационный файл с Environment переменными генерируется на основе app.toml.
Так это выглядит для разработчика: происходит сборка и деплой в локальный кластер, поднимается база, мигратор, кэши — и можно начать отладку. Локальное окружение получается максимально приближенным к продакшн.
Поговорим о тестировании
Классические боли тестирования в микросервисах: когда подходы, которые использовались в монолите по интеграционным тестам, в микросервисной архитектуре просто перестают работать. И завязывая десяток сервисов друг на друге в едином test suite, ты получаешь больше проблем, чем профита.
При этом, мы хотим покрывать наши тесты интеграционными кейсами для того, чтобы соблюсти пирамиду тестирования. Поэтому мы максимально стараемся использовать юнит-тесты, но при этом end-to-end тесты есть на критичных бизнес-путях. Для роутинга трафика между сервисами мы используем service mesh.
Какой существует подход? Например, у нас есть пять сервисов, которые взаимодействуют между собой. И мы хотим протестировать новую версию Service 3. Первое, что приходит в голову – это развернуть в тестовом окружении весь комплект сервисов, которые взаимодействуют между собой. Но помимо того, что ресурсы не безграничны, это может привести к увеличению времени выполнения тестов и плохо повлиять на их стабильность.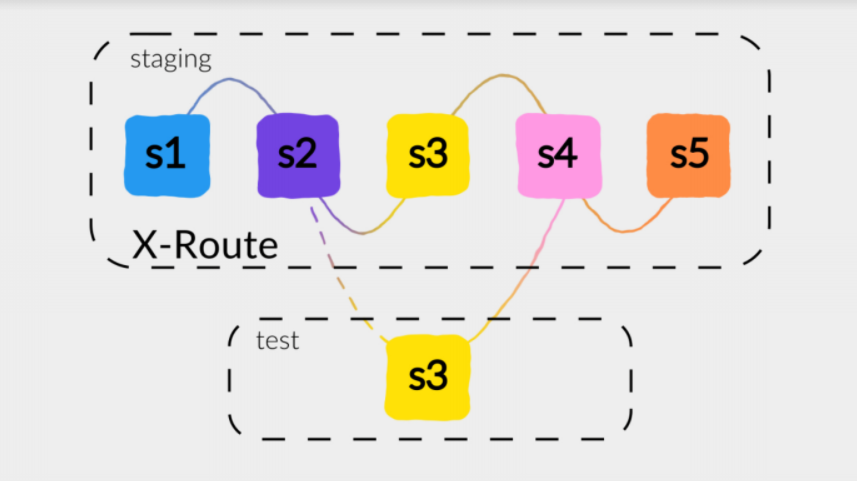
Поэтому мы поднимаем Service 3 в тестовом окружении. Добавляем в запрос специальный заголовок, балансировщик трафика его принимает, разбирает и понимает, что Service 2 должен сходить с этим заголовком в новую версию Service 3, находящуюся в тестовом окружении. Таким образом мы сохраняем наш staging стабильным, но при этом позволяем end to end тестам работать с новыми версиями сервисов.
Фактически основная часть задач разработчика уже завершена. Но деплой у нас тоже лежит на командах разработки.
Deploy и эксплуатация
Каковы проблемы деплоя? Helm – хороший инструмент, с его помощью можно создать высокоуровневое описание сервиса и всех его зависимостей. Тем не менее, с этим инструментом довольно трудно работать. У него много проблем и большое количество issues на github. Он не работает, когда необходимо поднять несколько кластеров для одного окружения, например, в staging или production. В этом случае все ломается, и helm не обеспечивает транзакционность деплоев. Ты не можешь гарантированно сказать, что у тебя все выкатилось в несколько окружений, и синхронно переключить трафик. В общем, начинается боль.
Поэтому команда архитектуры написала свой деплоер — Jibe (он пока еще не в open source, но такие планы у ребят есть). Он решает задачу деплоя в несколько кластеров.
От helm по большей части была важна только генерация Kubernetes-манифестов, поэтому можно было, например, использовать helm для генерации, а непосредственно для деплоя – Jibe. В дальнейшем можно будет генерировать манифесты самостоятельно.
Например, у нас есть два кластера, и сервис версии V5, которая задеплоена в оба кластера. Jibe, используя манифесты для новой версии, деплоит версию V6 в оба кластера: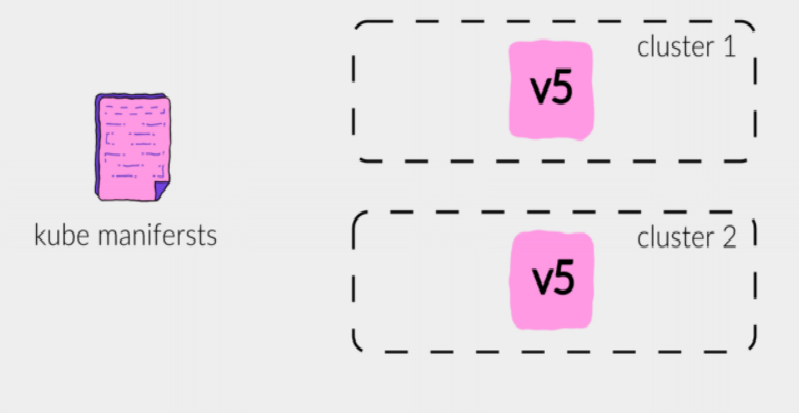
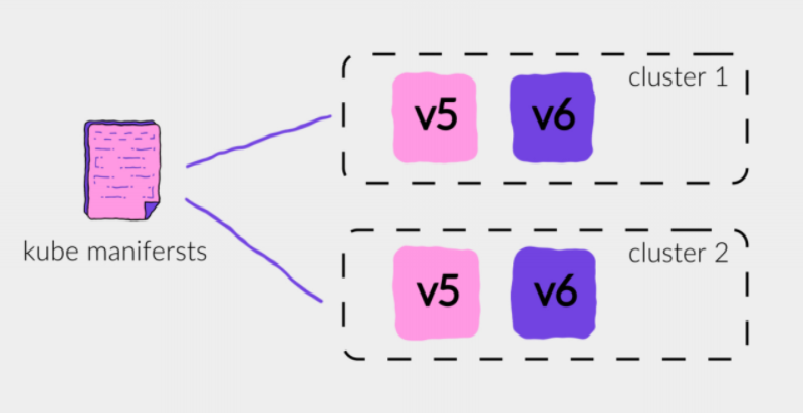
Трафик в это время все еще идет на V5.
После того, как readiness check отработал, мы переключаем трафик со старых версий на новые. В такой схеме мы обеспечили транзакционность выкатки сервисов, но транзакционность переключений трафика может страдать. Это значит, что в неожиданный момент на этом этапе может отвалиться сеть, и в одном кластере, трафик переключится, а в другом нет. На этот случай есть автоматика, которая проверяет связанность кластеров с деплоером. И если что-то пойдет не так, версия откатится, обеспечивая таким образом минимальный рассинхрон между версиями в проде. Если же переключение трафика прошло хорошо, старая версия гасится.
Что мы получаем? Несколько стадий деплоя, каждая из которых может идти на полуручном приводе. Мы можем откатывать сервисы либо с помощью Canary, либо blue-green деплоем, и при этом получаем гарантию консистентности версий сервисов на всех кластерах.
Чем нам помогает PaaS с точки зрения эксплуатации? Типичная боль инфраструктурных команд: когда продуктовые команды заложили слишком большие запросы на capacity, на CPU и память. И в итоге пулл по запросам забит, но утилизация машин намного ниже, чем хотелось бы, и железо простаивает.
Кроме того, разработчикам необходимо самостоятельно планировать необходимое количество ресурсов для сервисов, пытаться определить будущую нагрузку. Эти значения могут со временем устаревать. Нужно не забывать держать их в актуальном состоянии. В итоге мы получаем просто плохой scheduling, соседство различных сервисов на одной и той же ноде, которые могут друг друга аффектить, и неэффективное использование ресурсов.
В Kubernetes есть механизм Vertical Pod autoscaling, который на основании статистики использования сервиса за предыдущее время может динамически подстраивать requests уже при следующем деплое.
Мы пришли к тому, что requests вычисляются на основании статистики, что позволяет разработчикам не задумываться об этом вопросе. В начале, когда создается сервис, разработчику дается довольно большой запас для обработки будущей нагрузки. А когда статистика накапливается, requests выравниваются. При этом лимиты задаются достаточно высокими, чтобы в случае резких всплесков нагрузки, их можно было пережить.
Service discovery – часть, о которой разработчики тоже не хотят задумываться. Она должна быть скрыта за инфраструктурой, потому что иначе мы получаем зашивание URL непосредственно в конфигурации сервиса. Одни идут через ingress-контроллер, другие — по fqdn-адресу Kubernetes. Случайно пошли из прода в стейджинг – все сломалось. И появляется вопрос: как нам все это масштабировать, если у нас появляется новый кластер?
Что сделано у нас? В app.toml есть специальная секция с зависимостями сервиса: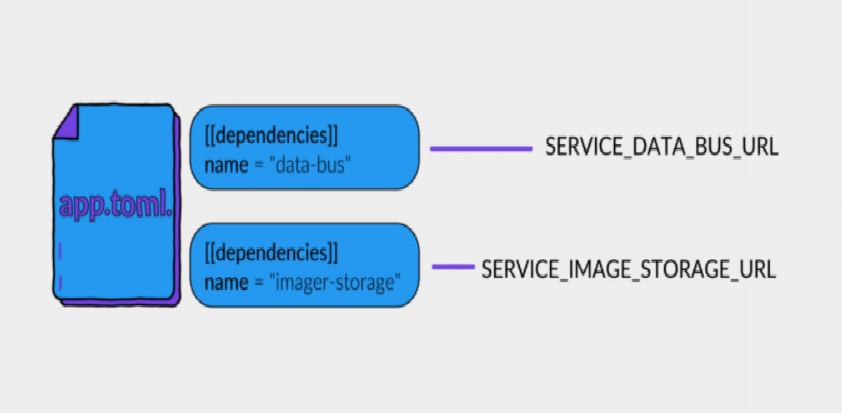
Таким образом, у нас решается две проблемы. Проблема конфигурации. Из названия сервиса по определенному шаблону формируется ENV-переменная, в которую подставится URL, куда нужно стучаться. И вторая: таким образом мы можем сформировать граф зависимости каждого сервиса не на основании статистики, а просто по манифестам.
И разработчик тоже получает преимущество. Не нужно указывать никакие URL, система сама автоматически подставит нужный путь. А балансер, который стоит перед сервисом, передаст коннект к нужному сервису нужной версии. Например, в продакшен в случае canary, или в staging — в случае такого кейса с тестированием.
Кроме того, автогенерируемые клиенты автоматически собирают все значения из ENV.
Кроме того, у нас есть опенсорсный инструмент Service Navigator (его можно будет посмотреть на нашем GitHub), который обеспечивает service mesh, и походы из одних сервисов в другие. Service Navigator собирает унифицированные метрики по всем взаимодействиям, и можно построить дашборды даже без участия и отправки метрик из сервисов. В навигаторе можно подключить разнообразные circuit breakers, переотправку запросов в случае ошибок. Все эти политики прозрачно настраиваются командой продуктовой разработки.
Под капотом используется Proxy Envoy, который балансит трафик, а Navigator занимается его динамической настройкой: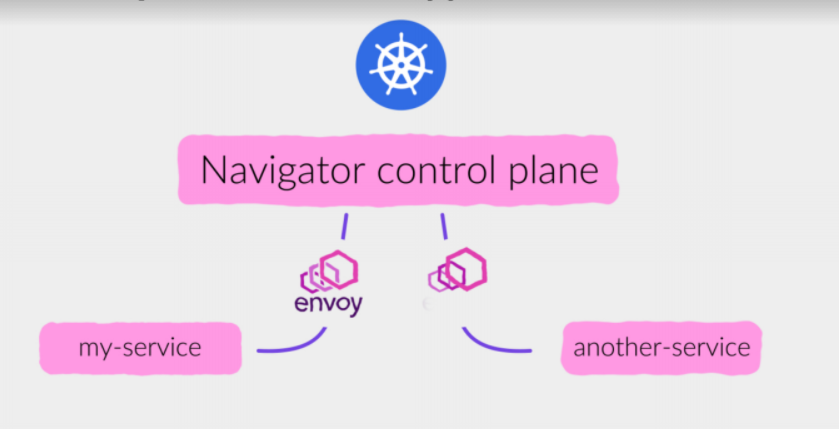
Таким образом у нас есть стандартные дашборды Observability, которые могут показать, что происходит с сервисом. По любому сервису можно получить единообразную информацию и даже отдебажить чужой сервис если метрики, которые для него написала команда разработки, недостаточно информативны.
Естественно, в Jagger есть связка с tracing. Envoy отправляет трейсы, и их все можно собрать в единую цепочку вызовов, чтобы посмотреть, где существует проблема.
Преимущества и недостатки PaaS
У любой системы есть недостатки. Главный недостаток PaaS в том, что со временем накапливается багаж сервисов. Они неплохо работают, поэтому никто не хочет их трогать, и бизнес-необходимости в этом нет. Кроме того, эти сервисы могут быть очень специфичными. Не все кейсы покрыты PaaS. Соответственно, миграция существующих сервисов может стать болевой точкой.
Важно соблюсти баланс между автоматизацией и гибкостью настройки.
Есть категория разработчиков, которым нравится возиться с низкоуровневыми деталями реализации, и они уже привыкли к имеющимся инструментам. Им может быть неприятно от того, что PaaS лишает их привычной части работы. Приходится тратить время на коммуникации. По нашему опыту, в итоге люди соглашаются с тем, что PaaS приносит больше радости, чем боли.
Однако PaaS в любом случае вносит ограничения в протокол взаимодействия, и их приходится либо принимать, либо обходить.
Какие у нас есть преимущества? Мы экономим время со стороны продуктовых команд, наш «зоопарк» технологий находится под контролем. Мы можем оповестить разработчиков о том, что вышла новая версия какой-нибудь библиотеки, или security patch. И радар технологий поддается осмыслению. Становится понятно, что используют команды у себя внутри в рамках большого Авито.
Кроме того, платформенная разработка развязывает себе руки, проводя любые операции по техническим усовершенствованиям внутри инфраструктуры без необходимости править код и helm-манифесты.
Выводы
PaaS обязателен для каждой компании, в которой количество разработчиков увеличивается от десятков до сотен.
PaaS можно рассматривать как продукт, позволяющий решить реальные проблемы людей и дать бизнесу возможность расти.
Я хочу закончить словами Расса Кокса о том, что разработка программного обеспечения появляется тогда, когда программирование добавляет время и других разработчиков. Это действительно так. И платформа — это то, что должно появиться в каждой крупной компании. И чем раньше компания осознает необходимость этого, тем меньше техдолга накопится за время, пока платформы нет.